纸上得来终觉浅,绝知此事要躬行。

1. 基础知识
1.1 定义
程序 = 数据结构 + 算法
数据结构是计算机存储、组织数据的一种方式。数据结构指互相之间存在一种或多种特定关系的数据元素的集合。精心选择的数据结构可以带来更高的运行或者存储效率。当然,数据结构也是一门研究数据以及数据之间存在关系的一门课程。掌握数据结构和相关算法,是解决实际问题一个基础的能力。
数据结构和算法是每个程序员需要掌握的基础知识之一,也是面试中跨不过的槛。目前关于Python算法和数据结构的中文资料比较欠缺,所以只是简单地介绍一下哈,更多的内容还是需要自己的深度的阅读和练习发掘。
1.2 分类
常见的数据结构分类
| 数据结构名称 | 英文名称 | 补充说明 |
|---|---|---|
| 堆栈 | Stack |
没有对应的内置数据结构 |
| 链表 | Linked List |
没有对应的内置数据结构 |
| 树 | Tree |
没有对应的内置数据结构 |
| 图 | Graph |
没有对应的内置数据结构 |
| 队列 | Queue |
没有对应的内置数据结构 |
| 堆 | Heap |
没有对应的内置数据结构 |
| 数组 | Array |
在 Python 中是列表 |
| 散列表 | Hash |
在 Python 中是字典 |
| 集合 | Set |
是 Python 中独特的数据类型 |
| 元组 | Tuple |
是 Python 中独特的数据类型 |
2. 数据结构
上面我们熟悉了
Python中的常见的数据结构,那它们在Python中是怎么使用的呢,下面我们就用实际的代码进行说明和演示。
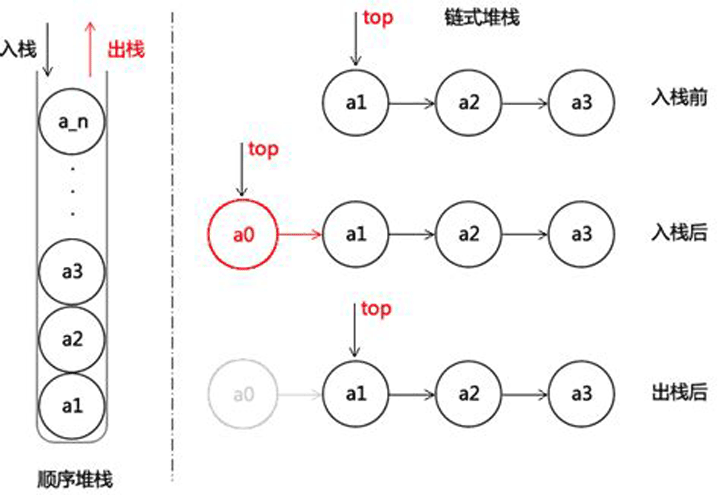
2.1 堆栈
- 堆栈是一种后进先出(
LIFO)的数据结构,其对应的操作只能在栈顶进行,为推入(push)和弹出(pop)。在Python中,可以使用一个List来表示堆栈,对应的操作为推入(append)和弹出(pop)。
In [1]: stack = [1, 2, 3]
In [2]: stack.append(4)
In [3]: stack.append(5)
In [4]: stack
Out[4]: [1, 2, 3, 4, 5]
In [5]: stack.pop()
Out[5]: 5
In [6]: stack.pop()
Out[6]: 4
In [7]: stack
Out[7]: [1, 2, 3]
- 在
Flask的依赖werkzeug中,有一个LocalStack的实现,详情可以参考如下代码示例或者上面的代码链接地址。
class LocalStack(object):
"""This class works similar to a :class:`Local` but keeps a stack
of objects instead. This is best explained with an example::
>>> ls = LocalStack()
>>> ls.push(42)
>>> ls.top
42
>>> ls.push(23)
>>> ls.top
23
>>> ls.pop()
23
>>> ls.top
42
They can be force released by using a :class:`LocalManager` or with
the :func:`release_local` function but the correct way is to pop the
item from the stack after using. When the stack is empty it will
no longer be bound to the current context (and as such released).
By calling the stack without arguments it returns a proxy that resolves to
the topmost item on the stack.
.. versionadded:: 0.6.1
"""
def __init__(self):
self._local = Local()
def __release_local__(self):
self._local.__release_local__()
def _get__ident_func__(self):
return self._local.__ident_func__
def _set__ident_func__(self, value):
object.__setattr__(self._local, '__ident_func__', value)
__ident_func__ = property(_get__ident_func__, _set__ident_func__)
del _get__ident_func__, _set__ident_func__
def __call__(self):
def _lookup():
rv = self.top
if rv is None:
raise RuntimeError('object unbound')
return rv
return LocalProxy(_lookup)
def push(self, obj):
"""Pushes a new item to the stack"""
rv = getattr(self._local, 'stack', None)
if rv is None:
self._local.stack = rv = []
rv.append(obj)
return rv
def pop(self):
"""Removes the topmost item from the stack, will return the
old value or `None` if the stack was already empty.
"""
stack = getattr(self._local, 'stack', None)
if stack is None:
return None
elif len(stack) == 1:
release_local(self._local)
return stack[-1]
else:
return stack.pop()
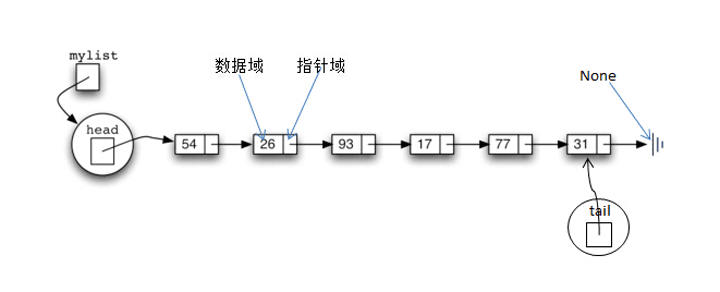
2.2 链表
- 链表是一个有序的序列,但是并不会按照线性的形式存储数据,而是在每一个节点里存放下一个节点的指针。由于不是按照顺序存储,所以链表在插入的时候可以达到
O(1)的时间复杂度。 - 但是
Python语言中,没有指针而只有引用,所以注意在Python里面是没有指针运算的。但是在Python里面,其实可以通过collections模块里面的deque来实现。而这里,我们通过类来实现单向链表。
class ListNode:
"""
A node in a singly-linked list.
"""
def __init__(self, data=None, next=None):
self.data = data
self.next = next
def __repr__(self):
return repr(self.data)
class SinglyLinkedList:
def __init__(self):
"""
Create a new singly-linked list.
Takes O(1) time.
"""
self.head = None
def __repr__(self):
"""
Return a string representation of the list.
Takes O(n) time.
"""
nodes = []
curr = self.head
while curr:
nodes.append(repr(curr))
curr = curr.next
return '[' + ', '.join(nodes) + ']'
def prepend(self, data):
"""
Insert a new element at the beginning of the list.
Takes O(1) time.
"""
self.head = ListNode(data=data, next=self.head)
def append(self, data):
"""
Insert a new element at the end of the list.
Takes O(n) time.
"""
if not self.head:
self.head = ListNode(data=data)
return
curr = self.head
while curr.next:
curr = curr.next
curr.next = ListNode(data=data)
def find(self, key):
"""
Search for the first element with `data` matching
`key`. Return the element or `None` if not found.
Takes O(n) time.
"""
curr = self.head
while curr and curr.data != key:
curr = curr.next
return curr # Will be None if not found
def remove(self, key):
"""
Remove the first occurrence of `key` in the list.
Takes O(n) time.
"""
# Find the element and keep a
# reference to the element preceding it
curr = self.head
prev = None
while curr and curr.data != key:
prev = curr
curr = curr.next
# Unlink it from the list
if prev is None:
self.head = curr.next
elif curr:
prev.next = curr.next
curr.next = None
def reverse(self):
"""
Reverse the list in-place.
Takes O(n) time.
"""
curr = self.head
prev_node = None
next_node = None
while curr:
next_node = curr.next
curr.next = prev_node
prev_node = curr
curr = next_node
self.head = prev_node
>>> lst = SinglyLinkedList()
>>> lst
[]
>>> lst.prepend(23)
>>> lst.prepend('a')
>>> lst.prepend(42)
>>> lst.prepend('X')
>>> lst.append('the')
>>> lst.append('end')
>>> lst
['X', 42, 'a', 23, 'the', 'end']
>>> lst.find('X')
'X'
>>> lst.find('y')
None
>>> lst.reverse()
>>> lst
['end', 'the', 23, 'a', 42, 'X']
>>> lst.remove(42)
>>> lst
['end', 'the', 23, 'a', 'X']
>>> lst.remove('not found')
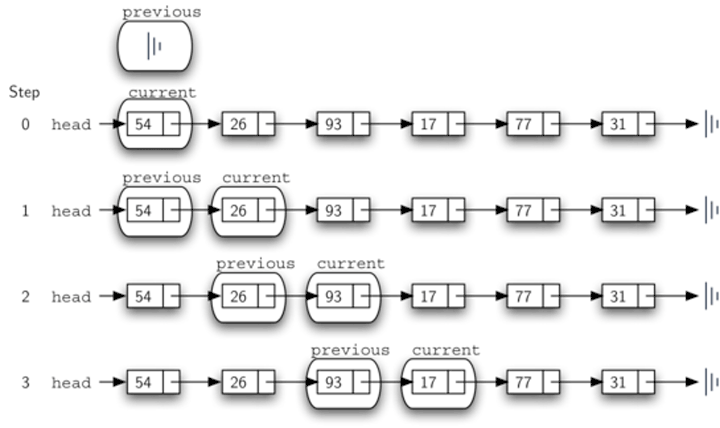
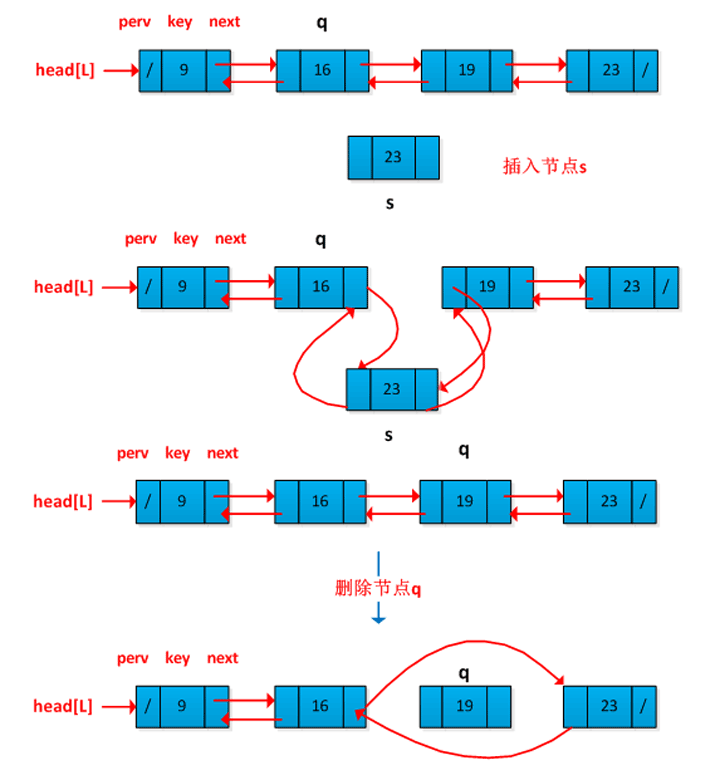
- 相对于单向列表,双向列表每一个节点都保存了上下两个节点的引用,可以看到它移除一个节点可以达到
O(1)的时间复杂度。
class DListNode:
"""
A node in a doubly-linked list.
"""
def __init__(self, data=None, prev=None, next=None):
self.data = data
self.prev = prev
self.next = next
def __repr__(self):
return repr(self.data)
class DoublyLinkedList:
def __init__(self):
"""
Create a new doubly linked list.
Takes O(1) time.
"""
self.head = None
def __repr__(self):
"""
Return a string representation of the list.
Takes O(n) time.
"""
nodes = []
curr = self.head
while curr:
nodes.append(repr(curr))
curr = curr.next
return '[' + ', '.join(nodes) + ']'
def prepend(self, data):
"""
Insert a new element at the beginning of the list.
Takes O(1) time.
"""
new_head = DListNode(data=data, next=self.head)
if self.head:
self.head.prev = new_head
self.head = new_head
def append(self, data):
"""
Insert a new element at the end of the list.
Takes O(n) time.
"""
if not self.head:
self.head = DListNode(data=data)
return
curr = self.head
while curr.next:
curr = curr.next
curr.next = DListNode(data=data, prev=curr)
def find(self, key):
"""
Search for the first element with `data` matching
`key`. Return the element or `None` if not found.
Takes O(n) time.
"""
curr = self.head
while curr and curr.data != key:
curr = curr.next
return curr # Will be None if not found
def remove_elem(self, node):
"""
Unlink an element from the list.
Takes O(1) time.
"""
if node.prev:
node.prev.next = node.next
if node.next:
node.next.prev = node.prev
if node is self.head:
self.head = node.next
node.prev = None
node.next = None
def remove(self, key):
"""
Remove the first occurrence of `key` in the list.
Takes O(n) time.
"""
elem = self.find(key)
if not elem:
return
self.remove_elem(elem)
def reverse(self):
"""
Reverse the list in-place.
Takes O(n) time.
"""
curr = self.head
prev_node = None
while curr:
prev_node = curr.prev
curr.prev = curr.next
curr.next = prev_node
curr = curr.prev
self.head = prev_node.prev
>>> lst = DoublyLinkedList()
>>> lst
[]
>>> lst.prepend(23)
>>> lst.prepend('a')
>>> lst.prepend(42)
>>> lst.prepend('X')
>>> lst.append('the')
>>> lst.append('end')
>>> lst
['X', 42, 'a', 23, 'the', 'end']
>>> lst.find('X')
'X'
>>> lst.find('y')
None
>>> lst.reverse()
>>> lst
['end', 'the', 23, 'a', 42, 'X']
>>> elem = lst.find(42)
>>> lst.remove_elem(elem)
>>> lst.remove('X')
>>> lst.remove('not found')
>>> lst
['end', 'the', 23, 'a']
- 在
Python里面,其实可以通过collections模块里面的deque来实现链表效果更佳。
>>> import collections
>>> lst = collections.deque()
# Inserting elements at the front
# or back takes O(1) time:
>>> lst.append('B')
>>> lst.append('C')
>>> lst.appendleft('A')
>>> lst
deque(['A', 'B', 'C'])
# However, inserting elements at
# arbitrary indexes takes O(n) time:
>>> lst.insert(2, 'X')
>>> lst
deque(['A', 'B', 'X', 'C'])
# Removing elements at the front
# or back takes O(1) time:
>>> lst.pop()
'C'
>>> lst.popleft()
'A'
>>> lst
deque(['B', 'X'])
# Removing elements at arbitrary
# indexes or by key takes O(n) time again:
>>> del lst[1]
>>> lst.remove('B')
# Deques can be reversed in-place:
>>> lst = collections.deque(['A', 'B', 'X', 'C'])
>>> lst.reverse()
deque(['C', 'X', 'B', 'A'])
# Searching for elements takes
# O(n) time:
>>> lst.index('X')
1
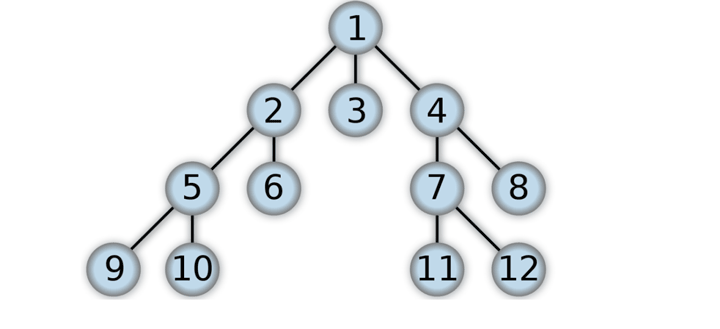
2.3 树
- 树是一种包含节点和边且拥有层级关系的数据结构,看起来像一个到挂着的树,即根朝上叶子朝下,它有以下几个特点。
- 每个节点拥有零个或者多个子节点
- 没有父节点的节点称为根节点
- 每一个非根节点有且只有一个父节点
- 除了根节点之外每个子节点可以分为多个不相交的子树
- 树分为有序树和无序树,而有序树应用很多,如二叉树和
B-tree树。二叉树是每个节点最多包含两个子树的树,子树有左右之分其顺序是不可以颠倒的。而二叉树又分为平衡二叉树、排序二叉树和完全二叉树。
def _build_tree_string(root, curr_index=0, delimiter='-'):
if root is None:
return [], 0, 0, 0
line1 = []
line2 = []
node_repr = str(root.value)
new_root_width = gap_size = len(node_repr)
l_box, l_box_width, l_root_start, l_root_end = \
_build_tree_string(root.left, 2 * curr_index + 1, delimiter)
r_box, r_box_width, r_root_start, r_root_end = \
_build_tree_string(root.right, 2 * curr_index + 2, delimiter)
if l_box_width > 0:
l_root = (l_root_start + l_root_end) // 2 + 1
line1.append(' ' * (l_root + 1))
line1.append('_' * (l_box_width - l_root))
line2.append(' ' * l_root + '/')
line2.append(' ' * (l_box_width - l_root))
new_root_start = l_box_width + 1
gap_size += 1
else:
new_root_start = 0
line1.append(node_repr)
line2.append(' ' * new_root_width)
if r_box_width > 0:
r_root = (r_root_start + r_root_end) // 2
line1.append('_' * r_root)
line1.append(' ' * (r_box_width - r_root + 1))
line2.append(' ' * r_root + '\\')
line2.append(' ' * (r_box_width - r_root))
gap_size += 1
new_root_end = new_root_start + new_root_width - 1
gap = ' ' * gap_size
new_box = [''.join(line1), ''.join(line2)]
for i in range(max(len(l_box), len(r_box))):
l_line = l_box[i] if i < len(l_box) else ' ' * l_box_width
r_line = r_box[i] if i < len(r_box) else ' ' * r_box_width
new_box.append(l_line + gap + r_line)
return new_box, len(new_box[0]), new_root_start, new_root_end
class Node(object):
def __init__(self, value, left=None, right=None):
self.value = value
self.left = left
self.right = right
def __str__(self):
lines = _build_tree_string(self, delimiter='-')[0]
return '\n' + '\n'.join((line.rstrip() for line in lines))
>>> root = Node(1)
>>> root.left = Node(2)
>>> root.right = Node(3)
>>> root.left.right = Node(4)
>>> print(root)
__1__
/ \
2 3
\
4
2.4 图
- 图是网状结构的一种抽象表示方式,由定点的有穷非空集合和定点之间的边的集合组成。使用比较广泛,如人物关系、地图、社交网络等等。
- 下面示例代码就是演示一个地图的图的表示方法,计算最少换乘、最短路线等等。而要选择路线就要遍历图,遍历最常用的就是深度优先遍历(
DFS)和广度优先遍历(BSF)。
In [1]: graph = {'A': set(['B', 'C']),
...: 'B': set(['A', 'D', 'E']),
...: 'C': set(['A', 'F']),
...: 'D': set(['B']),
...: 'E': set(['B', 'F']),
...: 'F': set(['C', 'E'])}
In [2]: def dfs_paths(graph, start, goal, path=None):
...: if path is None:
...: path = [start]
...: if start = goal:
...: yield path
...: for next in graph[start] - set(path):
...: yield from dfs_paths(graph, next, goal, path + [next])
In [3]: list(dfs_paths(graph, 'A', 'F'))
Out[3]: [['A', 'B', 'E', 'F'], ['A', 'C', 'F']]
In [1]: graph = {'A': set(['B', 'C']),
...: 'B': set(['A', 'D', 'E']),
...: 'C': set(['A', 'F']),
...: 'D': set(['B']),
...: 'E': set(['B', 'F']),
...: 'F': set(['C', 'E'])}
In [2]: def bfs_paths(graph, start, goal):
...: queue = [(start, [start])]
...: while queue:
...: (vertex, path) = queue.pop(0)
...: for next in graph[vertex] - set(path):
...: if next == goal:
...: yield path + [next]
...: else:
...: queue.append((next, path + [next]))
In [3]: list(bfs_paths(graph, 'A', 'F'))
Out[3]: [['A', 'C', 'F'], ['A', 'B', 'E', 'F']]
3. 容器
常见的数据结构可以统称为容器
容器分类
- 序列:
String、Bytes、List、Tuple、Byte Arrays、Range - 映射:
Dict - 集合:
FrozenSet、Set
判断方法
In [1]: import collections
In [2]: isinstance([1, 2], collections.Container)
Out[2]: True
In [3]: isinstance(b'abc', collections.Container)
Out[3]: True
In [4]: isinstance(range(10), collections.Container)
Out[4]: True
3.1 池化
池化 = 缓存机制
- 我们发现下面示例中,仅仅是多添加了一个感叹号,两个对象就不同了且
id函数的返回值也是不同的,这是为什么呢?这就涉及了关于字符串的池化。
In [1]: s1 = 'foo'
In [2]: s2 = 'foo'
In [3]: s1 is s2
Out[3]: True
In [4]: s1 = 'foo!'
In [5]: s2 = 'foo!'
In [6]: s1 is s2
Out[6]: False
In [7]: id(s1), id(s2)
Out[7]: (4410350144, 4409281480)
- 池化是一种缓存的机制,相同的名字重复的出现在不同的命名空间中,是有必要共享实例的,这样避免字符串占用过多的内存。同时,对单字符做出优化,是它不需要每次都向内核申请分配内存。
- 经过阅读
CPython中的源码,发现有如下这段代码,也就是说池化只针对于字母、数字和下划线。而感叹号不在这个范围内,所以并没有缓存起来。
/* all_name_chars(s): true iff s matches [a-zA-Z0-9_]* */
static int
all_name_chars(PyObject *o)
{
const unsigned char *s, *e;
if (!PyUnicode_IS_ASCII(o))
return 0;
s = PyUnicode_1BYTE_DATA(o);
e = s + PyUnicode_GET_LENGTH(o);
for (; s != e; s++) {
if (!Py_ISALNUM(*s) && *s != '_')
return 0;
}
return 1;
}
- 如果我们还是需要能够返回
True的话,就需要使用如下方式了。
In [8]: import sys
In [9]: s1 = 'foo!'
In [9]: s2 = 'foo!'
In [10]: sys.intern(s1) is sys.intern(s2)
Out[10]: True
3.2 拆包
拆包 = 解包
- 以下是一些简单示例,如果我们对于拆包之后的内容不感兴趣,可以把它复制给占位符
_,表示我想关心这个变量的值是什么。
In : a, b = [1, 2]
In : a
Out: 1
In : b
Out: 2
In : a, b = {'q': 1, 'p': 2}
In : a, b
Out: ('q', 'p')
In : _, b = 1, 2
In : b
Out: 2
- 拆包操作也是支持嵌套的,而且在
Python3中,还支持在range函数中使用*表达剩余部分的功能,但且一个表达式中只能使用一次。
In : [a, (b, c)] = [[1, 2], [3, 4]]
In : a, b, c
Out: ([1, 2], 3, 4)
In : a, b, *rest = range(5)
In : a, b, rest
Out: (0, 1, [2, 3, 4])
In : a, b, *rest = range(2)
In : a, b, restOut: (0, 1, [])
In : a, *part, b, c = range(5)
In : a, b, c, part
Out: (0, 3, 4, [1, 2])
In : *head, a, b, c = range(5)
In : a, b, c, head
Out: (2, 3, 4, [0, 1])



