压缩工具中的神器: 压缩比高,速度快,性能好!

1. 工具介绍
主要介绍 zstd 工具的作用和性能测试
我们称 Zstandard 或 Zstd 是一种快速的无损压缩算法,是针对 zlib 级别的实时压缩方案,以及更好的压缩比。它由一个非常快的熵阶段,由 Huff0 和 FSE 库提供。这个项目是作为开源的 BSD 许可收费的库,以及一个生成和解码 .zst 格式。
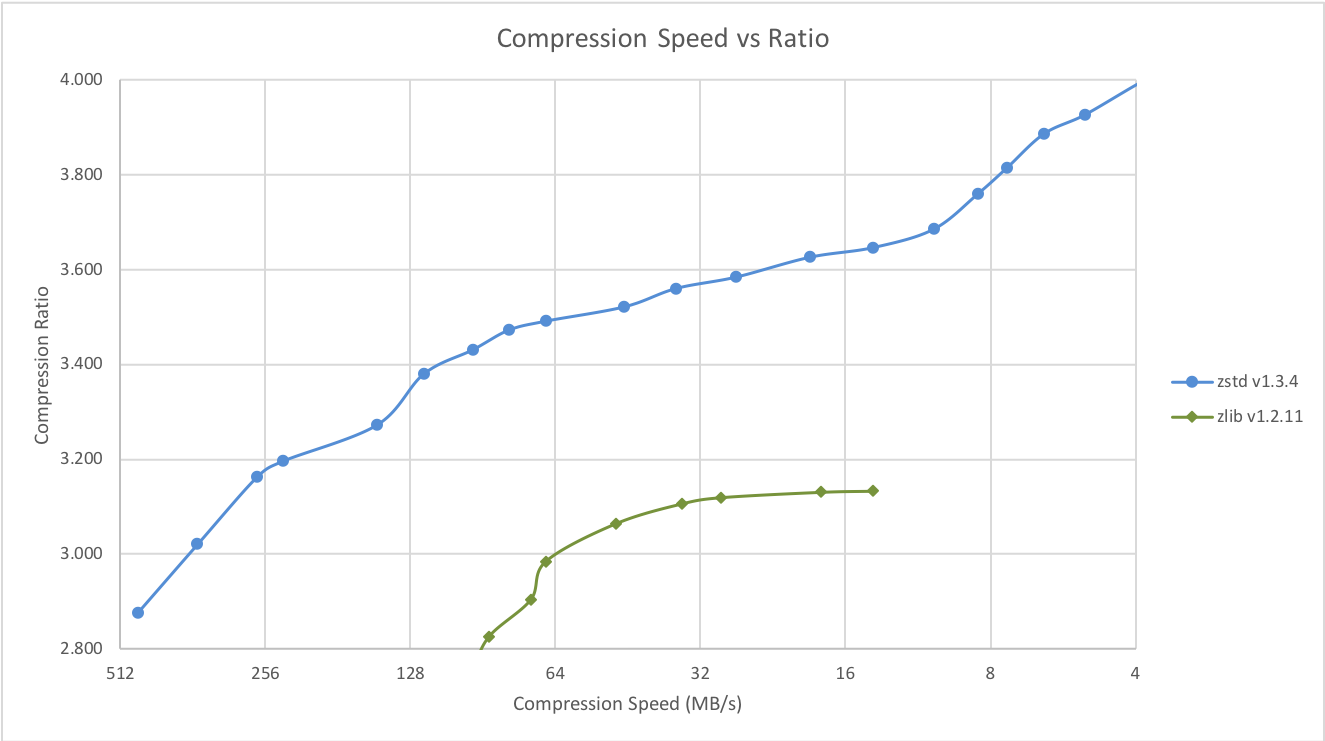
- 性能测试对比
| Compressor name | Ratio | Compression | Decompress. |
|---|---|---|---|
| zstd 1.4.4 -1 | 2.884 | 520 MB/s | 1600 MB/s |
| zlib 1.2.11 -1 | 2.743 | 110 MB/s | 440 MB/s |
| brotli 1.0.7 -0 | 2.701 | 430 MB/s | 470 MB/s |
| quicklz 1.5.0 -1 | 2.238 | 600 MB/s | 800 MB/s |
| lzo1x 2.09 -1 | 2.106 | 680 MB/s | 950 MB/s |
| lz4 1.8.3 | 2.101 | 800 MB/s | 4220 MB/s |
| snappy 1.1.4 | 2.073 | 580 MB/s | 2020 MB/s |
| lzf 3.6 -1 | 2.077 | 440 MB/s | 930 MB/s |
Zstd 还可以压缩速度为代价提供更强的压缩比,Speed vs Rtrade 可以通过小增量进行配置。在所有设置中,解压速度保持不变,并在所有 LZ压缩算法( 比如 zlib 或者lzma) 共享的属性中保持不变。
以前的压缩方式,都是适用于典型文件和二进制的压缩方案( MB/GB)的情况。然而,要压缩的数据量越小,压缩就越困难。这是所有压缩算法都存在的问题,原因是压缩算法从过去的数据中学习如何压缩未来的数据。但是在一个新的数据集的开始,没有“过去”可以参考。
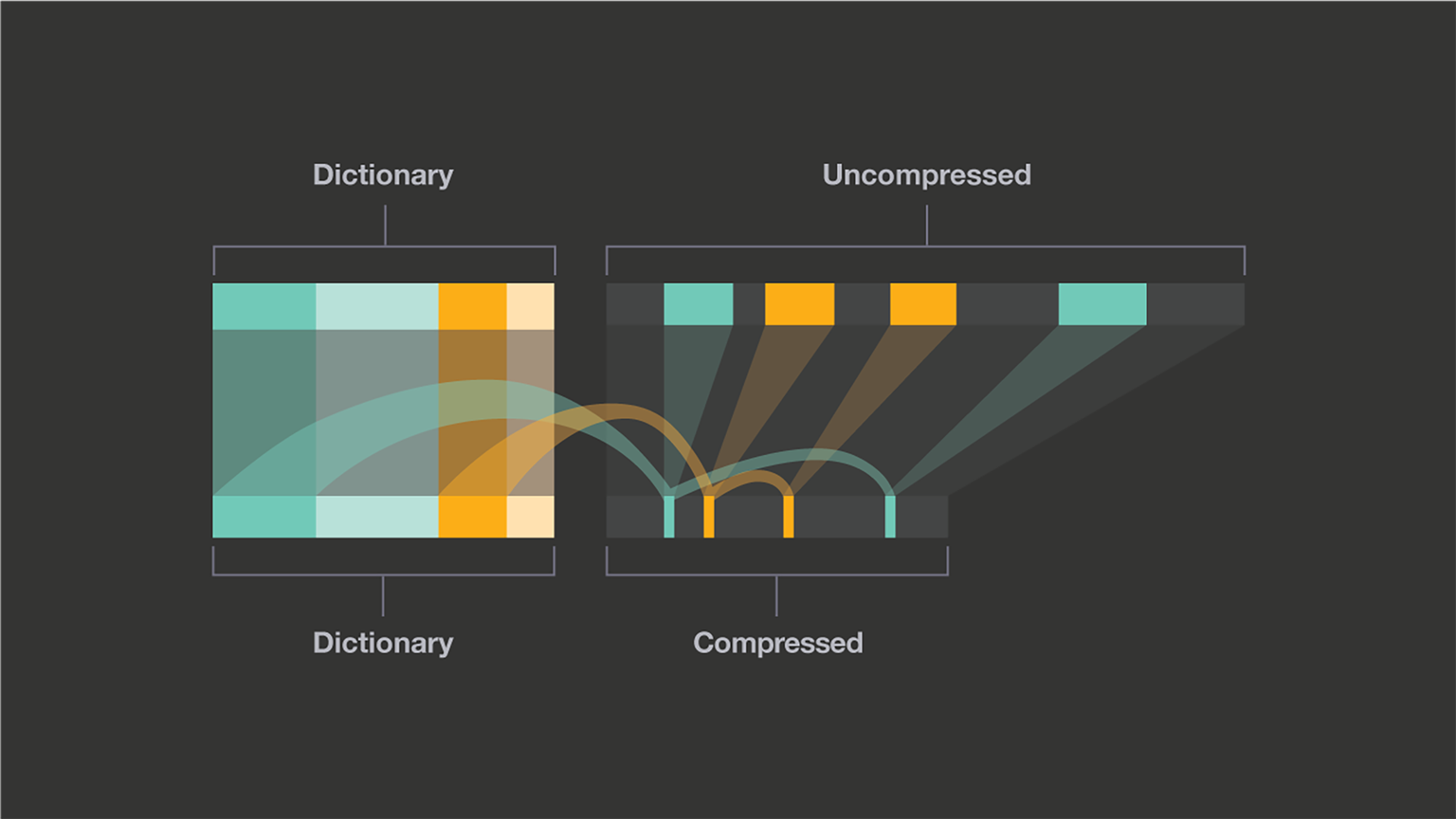
为了解决这种情况,Zstd 提供了一种新的训练模式,可以使用这种模式对所选数据类型的算法进行调优。 训练 Zstandard 是通过提供一些样本(每个样本一个文件)来实现的,训练的结果存储在称为“字典”的文件中,该文件必须在压缩和解压缩之前加载。使用此字典,可以在小数据上实现的压缩率大大提高。
以下示例,使用由 github 公共 API 创建的 github 用户示例集。它由大约 10K 条记录组成,每条记录 1KB 左右。
- 小数据压缩的案例
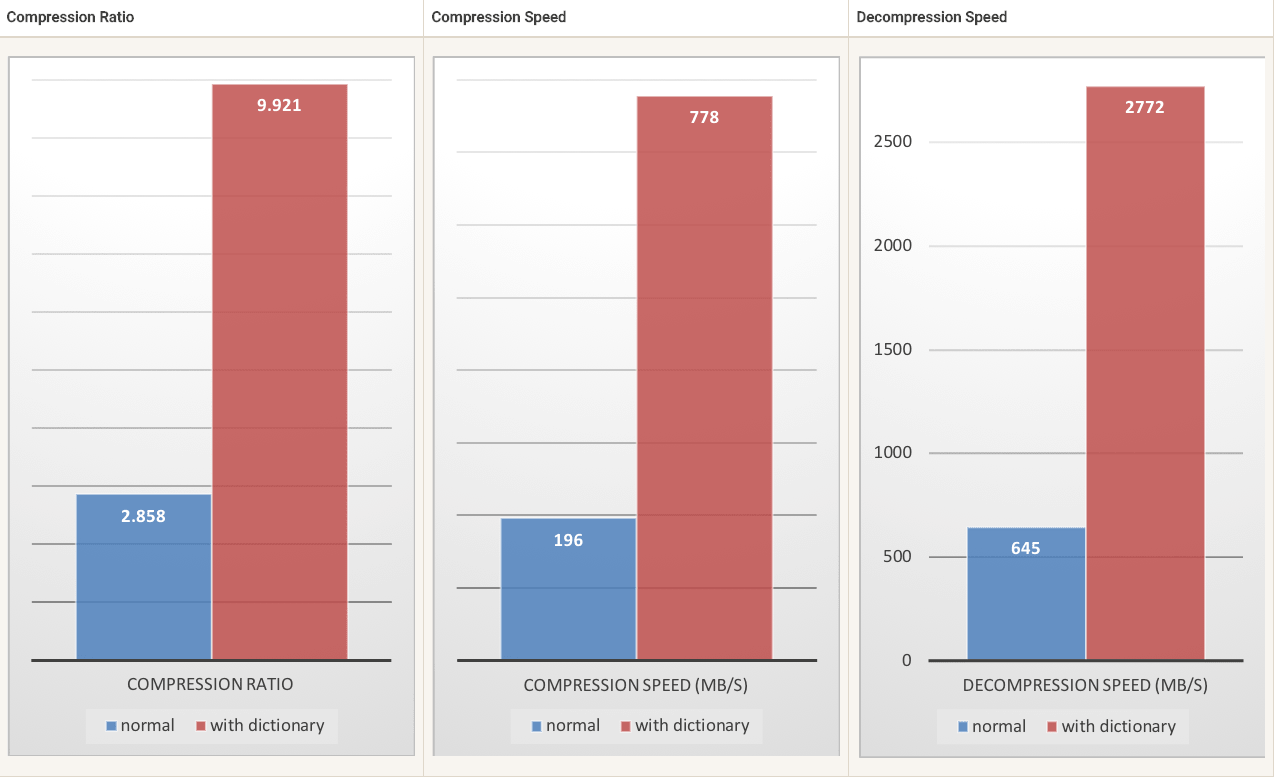
如果在一组小的数据样本中存在某种相关性,那么训练就是有效的。一个字典的数据越具体,它的效率就越高(没有通用字典)。因此,为每种类型的数据部署一个字典将带来最大的好处。字典增益在前几个 KB 中最有效。然后,压缩算法将逐步使用先前解码的内容,以更好地压缩文件的其余部分。
- 字典压缩使用示例
# 训练字典
$ zstd --train FullPathToTrainingSet/* -o dictionaryName
# 用字典压缩
$ zstd -D dictionaryName FILE
# 用字典解压缩
$ zstd -D dictionaryName --decompress FILE.zst

- 提供客户端工具
2. 参数命令
主要介绍 zstd 工具的安装和全部的参数命令
- 安装方式
# Ubuntu
$ apt install zstd
# CentOS
$ yum install zstd
# 编译安装
$ git clone https://github.com/facebook/zstd.git
$ cd zstd; make; sudo make install
- 参数命令
$ zstd --help
使用方式 :
zstd [args] [FILE(s)] [-o file]
参数选项 :
-# : 压缩级别(1-19,默认值为3)
-d : 解压
-D file: 使用文件作为字典
-o file: 结果存储在文件中
-f : 在没有提示的情况下覆盖输出并(解压)压缩链接
--rm : 成功解压缩后删除源文件
-k : 保存源文件(默认)
-h/-H : 显示帮助/长帮助并退出
高级选项 :
-V : 显示版本号并退出
-v : 详细模式
-q : 静默输出
-c : 强制写入标准输出
-l : 输出zstd压缩包中的信息
--ultra : 启用超过19级,最多22级(需要更多内存)
-T# : 使用几个线程进行压缩(默认值:1个)
-r : 递归地操作目录
--format=gzip : 将文件压缩为.gz格式
-M# : 为解压设置内存使用限制
字典生成器 :
--train ## : 从一组训练文件中创建一个字典
--train-cover[=k=#,d=#,steps=#] : 使用带有可选参数的cover算法
--train-legacy[=s=#] : 有选择性地使用遗留算法(默认值:9)
-o file : “file”是字典名(默认:字典)
--maxdict=# : 将字典限制为指定大小(默认值:112640)
--dictID=# : 强制字典ID为指定值(默认:随机)
性能测试参数 :
-b# : 基准测试文件,使用#压缩级别(默认为1)
-e# : 测试从-bX到#的所有压缩级别(默认值:1)
-i# : 最小计算时间(秒)(默认为3s)
-B# : 将文件切成大小为#个独立块(默认:无块)
--priority=rt : 将进程优先级设置为实时
3. 使用技巧
主要介绍一些关于 zstd 工具的使用示例和参数解释
- 简单使用
# 将一个文件压缩成一个后缀为.zst的新文件
# 如果命令后面没有文件或文件为-的话,则读取标准输入
$ zstd file
# 在压缩操作后删除源文件
# 默认情况下,源文件在成功压缩或解压缩后不会被删除
$ zstd --rm file
# 解压zst压缩包
$ zstd -d file.zst
# 解压zst压缩包到标准输出
$ zstd -dc file.zst
# 查看zst压缩包
$ zstd -l file.zst
$ zstdcat file.zst
- 高级用法
# 输出详细信息
$ zstd -v file
$ zstd -v -d file.zst
# 压缩一个文件同时指定压缩级别(19最高,0最低,3为默认)
$ zstd -level file
$ zstd -9 file
# 使用更多的内存(压缩和解压时)以达到更高的压缩比
$ zstd --ultra -level file
# 解压缩为单进程
# 多个进程并发执行压缩过程(0表示自动使用所有CPU核心)
$ zstd -T0 file
$ zstd -T4 file
$ zstd -T4 -d file.zst
4. 参考文档
授人玫瑰,手有余香!



