纸上得来终觉浅,绝知此事要躬行。

1. 多路处理模型
多路处理模型(
MPM)是将模块结构化,针对不同的环境进行优化。
Prefork
- 实现了一个非线程型的、预派生的
Web服务器。 - 一般适合波动比较大的网站,可以将最大进程数调大,应对突发的大访问量。但不能超过服务器的最大负荷,因为派生子进程也会消耗资源,可能会导致服务器的雪崩效应。
Worker
- 使用了多进程,每个进程再派生出多个线程,处理用户请求。
- 一般适合波动不大的网站,指定启动的进程数和线程数,因为大访问的时候可能会超过设置的
m*n数量导致后续响应无法处理。但是,比较合理的做法是对每个worker分配合理的负荷。
event
event模型是worker模型的变种,产生多个进程,每个进程响应多个请求。- 它将服务器进程从连接中分离出来,在开启
KeepAlive场合下相对于worker模式能够承受更高的并发负载。
2. 常见 I/O 访问模型
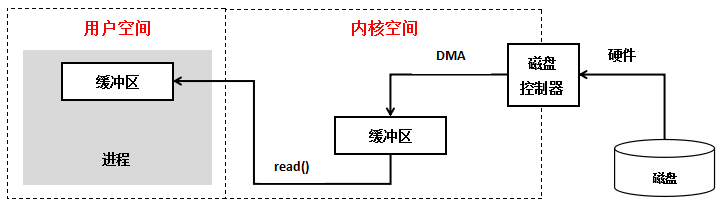
当I/O发生的时候就会涉及到对象和步骤的操作,我们这里以网络I/O的read为例。它会涉及到两个系统对象,一个是调用这个I/O操作的进程或线程,另一个就是系统内核。当read操作发生时,第一步会等待数据准备(磁盘到内核内存),第二步会将数据从内核拷贝到进程中去(内核内存到进程内存)。
2.1 古老模型
阻塞型 I/O 模型
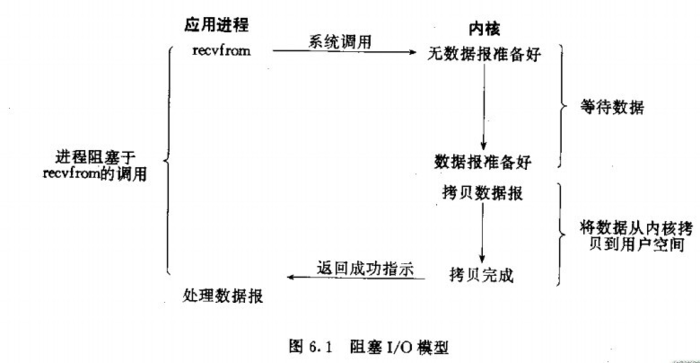
- 特点
- 特点就是在
I/O执行的两个阶段(等待数据和拷贝数据)中,应用进程都被阻塞。
- 特点就是在
- 注意
- 阻塞型
I/O中一个进程通常只能处理单路IO请求,而Prefork和Worker则可以处理两路I/O,分别是磁盘I/O和网络I/O。
- 阻塞型
- 举例:去饭馆吃面
- 第一阶段:每个人都需要站着排队等待面做好,啥都干不了。
- 第二阶段:面做好了,自己需要端到自己的座位上吃面,依旧阻塞。
非阻塞 I/O 模型
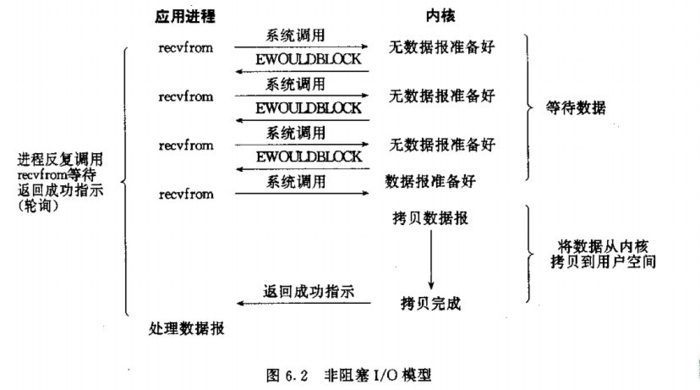
- 特点
- 非阻塞型
I/O中,应用进程需要不断的主动询问第一阶段(kernel数据准备)是否完成
- 非阻塞型
- 注意
- 应用进程在第一阶段虽然不用一直阻塞,但是需要不断的主动询问,基本属于忙等待状态。
- 所以非阻塞型不一定比阻塞型就好,而且第二阶段还是都需要等待,即第二阶段一直阻塞。
- 举例:去饭馆吃面
- 第一阶段:叫面之后,自己还是需要不断地询问面是否已经做好了
- 第二阶段:面做好了,自己需要端到自己的座位上吃面,依旧阻塞。
2.2 现代模型
复用 I/O 模型
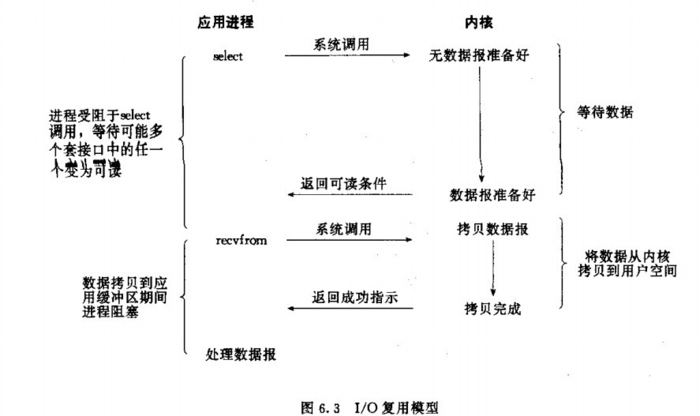
- 特点
- 复用型
I/O模型,即多路I/O模型。 - 在应用进程和内核中间加一个代理,所有的请求都交给代理去处理,自己只需要等待结果就可以了。
- 复用型
- 注意
- 这个代理就是我们熟知的
select和poll模型,两者基本没有区别,只是开发的厂商不一样而已。 - 即使有了代理,依然还是阻塞的,因为有可能会阻塞在代理上,如
select和poll。 - 有了代理最大的好处是,即使阻塞了但代理还可以接受其他用户请求,第二阶段依旧阻塞。
- 对性能没有太大的提升,因为还是阻塞的,只是能够处理其他请求而已。
- 这个代理就是我们熟知的
- 举例:去饭馆吃面
- 第一阶段:面馆有老板娘了,想吃面或吃菜都给老板娘说,自己不需要再不断地问了。
- 第二阶段:但面或菜做好了,自己需要端到自己的座位上吃,老板娘只是收钱的,依旧阻塞。
事件驱动 IO 模型
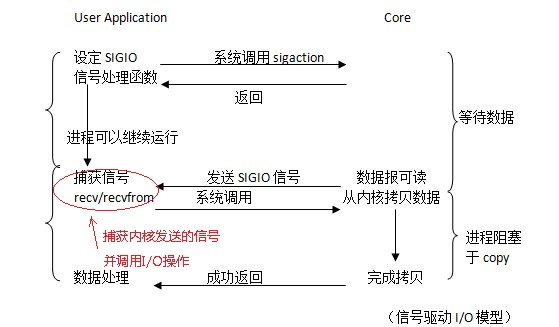
- 特点
- 在第一阶段中,应用进程只需要通知内核加载磁盘内容,加载完成之后,内核会通知已经完成。
- 注意
- 在第一阶段中,应用进程还可以响应其他请求,而不怕阻塞在代理上。
- 在第二阶段,将数据从内核拷贝到进程中去,依旧处于阻塞的状态。
- 可以理解为,一个进程可以响应多个请求,就是
event模型能够处理多个请求的原因。 - 这里的性能不一定非常好,因为
I/O的第二阶段还是处于阻塞的状态。
- 举例:去饭馆吃面
- 第一阶段:面馆聘请了多个服务员,想吃面或吃菜都给服务员说,自己等待的时候可以干别的事。
- 第二阶段:但面或菜做好了,自己还是需要端到自己的座位上吃,因为服务只负责给后厨通知。
异步 IO 模型
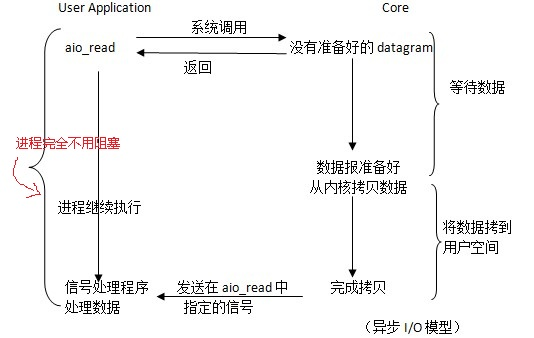
- 特点
- 异步
I/O模型,应用进程只需要通知内核,内核默默的完成第一和第二阶段,完成之后通知进程已经完成了。
- 异步
- 注意
- 真正的实现了不阻塞、不等待的模型。
- 一个进程可以响应多个请求,性能极大地提升,如
AIO。
- 触发
- 水平触发:完成之后通知应用进程,如果没有收到,会一直发送,直到处理位置,非常消耗资源。
- 边缘触发:完成之后通知应用进程,只通知一次,如果没有处理则存放起来并告诉其位置,比较好的方式。
- 举例:去饭馆吃面
- 第一阶段:面馆聘请了多个服务员,想吃面或吃菜都给服务员说,自己等待的时候可以干别的事。
- 第二阶段:面或菜做好了,服务员会给你端到自己的座位上,自己只需要吃就可以了。
2.3 select 和 epoll
select同步模型- 每次调用
select都需要把fd(文件句柄)集合从用户态拷贝到内核态,这个开销在fd很多时会很大 - 同时每次调用
select都需要在内核遍历传递进来的所有 fd,这个开销在 fd 很多时也会很大(自己定期去看) select支持的文件描述符数量太小了,默认为1024,但可以自行调整,超过1024可能导致性能下降
- 每次调用
epoll异步模型- 支持一个进程打开大数量的
socket描述符 I/O效率不随fd数量的增长而线性下降(不用自己定期去看)- 使用
mmap加速内核与用户空间的消息传递 - 支持边缘处罚和水平触发 080
- 支持一个进程打开大数量的

3. 知识扩展
3.1 为什么使用 HTTPS 呢?
重点:主要是为了防止网站劫持
使用HTTPS的潮流应该是Google开创的,最初是为了安全性,同时会优先收录和展示HTTPS的页面,于是就推动整个行业都在往HTTPS转换。毕竟Google是最大的流量入口,而且大家也好歹有点技术追求。国内的互联网公司可不是靠Google吃饭的,而是靠百度。而百度也是从2015年初才开始全面使用HTTPS协议。
- 防止链路层劫持
防止自家的App及网页被运营商劫持,被运营商“强行插入”广告甚至是竞争对手的广告。
运营商劫持有两种,第一类是域名劫持或者污染 DNS,目标域名会被恶意地错误解析到其他IP地址,显示劫持者自己制定的广告内容或者直接造成用户无法正常使用服务;第二类是数据劫持,对于返回的内容会在其中强行插入弹窗或嵌入式广告等其他内容,达到做广告的目的。
一般来说,各家互联网公司遭遇到的运营商劫持都是第二种,技术原理大致如下所述。通过劫持HTTP来实现,在用户与其目标网络服务所建立的专用数据通道中,监视数据信息进行匹配,就会在目标服务器返回的数据流中插入广告的网络数据报文。最后的结果是用户端程序,无论PC端还是移动端的网页或者客户端,只要是使用HTTP传递的数据都会被插入并以弹出广告的新窗口,然后彻底污染了原有页面。
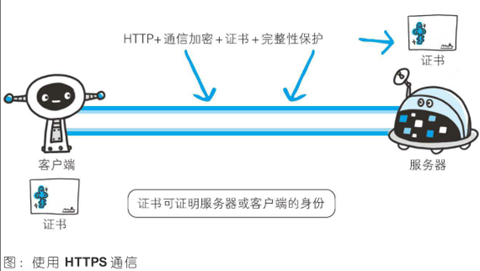
为了防止这种劫持,各大互联网公司只好选择HTTPS,进行数据加密而防止数据被篡改加入广告。关于HTTPS 的通信步骤,可以参考下图中的通信机制。

既然HTTPS那么好,既安全而且又有这样的好处,为什么现在还有很多网站还是使用HTTP?原因大致有三个:一是开启 HTTPS要申购SSL证书,每年要在证书上花费不菲的费用;二是使用HTTPS服务器端需要占用CPU资源进行加解密操作;三是HTTPS协议的多几次握手,导致网络耗时变长。
- 手机和电脑的不断发展
随着手机和电脑的不断推陈出新,收的网络已经发展到了4G+,而电脑的配置更是不断提高。对于网站的安全做好的很有利的群众基础,使得很容易的支持SSL的加密算法,为用户提供更为安全的服务。
3.2 长连接好还是短连接好呢
重点:根据业务来决定
- HTTP 协议与 TCP/IP 协议的关系
HTTP的长连接和短连接本质上是TCP长连接和短连接。HTTP属于应用层协议,在传输层使用TCP协议,在网络层使用IP协议。IP协议主要解决网络路由和寻址问题,TCP协议主要解决如何在IP层之上可靠的传递数据包,使在网络上的另一端收到发端发出的所有包,并且顺序与发出顺序一致。TCP有可靠,面向连接的特点。
- 理解 HTTP 协议是无状态的
HTTP协议是无状态的,指的是协议对于事务处理没有记忆能力,服务器不知道客户端是什么状态。也就是说,打开一个服务器上的网页和你之前打开这个服务器上的网页之间没有任何联系。HTTP是一个无状态的面向连接的协议,无状态不代表HTTP不能保持TCP连接,更不能代表HTTP使用的是UDP协议。
- TCP 连接的两个重要过程
当网络通信时采用TCP协议时,在真正的读写操作之前,server与client之间必须建立一个连接,当读写操作完成后,双方不再需要这个连接 时它们可以释放这个连接,连接的建立是需要三次握手的,而释放则需要4次握手,所以说每个连接的建立都是需要资源消耗和时间消耗的
- HTTP 协议的长连接和短连接
在HTTP/1.0中,默认使用的是短连接。也就是说,浏览器和服务器每进行一次HTTP操作,就建立一次连接,但任务结束就中断连接。如果客户端浏览器访问的某个HTML或其他类型的Web页中包含有其他的Web资源,如JavaScript文件、图像文件、CSS文件等;当浏览器每遇到这样一个Web资源,就会建立一个HTTP会话。
但从HTTP/1.1起,默认使用长连接,用以保持连接特性。使用长连接的HTTP协议,会在响应头有加入这行代码:
Connection:keep-alive
在使用长连接的情况下,当一个网页打开完成后,客户端和服务器之间用于传输HTTP数据的TCP连接不会关闭,如果客户端再次访问这个服务器上的网页,会继续使用这一条已经建立的连接。Keep-Alive不会永久保持连接,它有一个保持时间,可以在不同的服务器软件中设定这个时间。实现长连接要客户端和服务端都支持长连接。
HTTP协议的长连接和短连接,实质上是TCP协议的长连接和短连接。
- TCP 的短连接
TCP短连接的情况,client向server发起连接请求,server接受client的连接请求,双方建立连接。client向server发送消息,server回应client,然后一次读写就完成了,这时候双方任何一个都可以发起close操作,不过一般都是client先发起close操作。
为什么呢?一般的server不会回复完client后立即关闭连接的,当然不排除有特殊的情况。从上面的描述看,短连接一般只会在client/server间传递一次读写操作。
短连接的优点在于,管理起来比较简单,存在的连接都是有用的连接,不需要额外的控制手段。
- TCP 的长连接
TCP长连接的情况,client向server发起连接请求,server接受client的连接请求,双方建立连接。client与server完成一次读写之后,它们之间的连接并不会主动关闭,后续的读写操作会继续使用这个连接。
首先说一下TCP/IP详解上讲到的TCP 保活功能,保活功能主要为服务器应用提供,服务器应用希望知道客户主机是否崩溃,从而可以代表客户使用资源。如果客户已经消失,使得服务器上保留一个半开放的连接,而服务器又在等待来自客户端的数据,则服务器将应远等待客户端的数据,保活功能就是试图在服务器端检测到这种半开放的连接。
如果一个给定的连接在两小时内没有任何的动作,则服务器就向客户发一个探测报文段,客户主机必须处于以下4个状态其中任意的一种:
- 客户主机依然正常运行,并且从服务器可达,服务器在两小时后将保活定时器复位。
- 客户主机已经崩溃,并且关闭或者正在重新启动。在任何一种情况下,客户的
TCP都没有响应。服务端将不能收到对探测的响应,并在75秒后超时。服务器总共发送10个这样的探测 ,每个间隔75秒。如果服务器没有收到一个响应,它就认为客户主机已经关闭并终止连接。 - 客户主机崩溃并已经重新启动。服务器将收到一个对其保活探测的响应,这个响应是一个复位,使得服务器终止这个连接。
- 客户机正常运行,但是服务器不可达,这种情况与
2类似,TCP能发现的就是没有收到探查的响应。
服务器通过判断客户端是否存活,来保证是否需要关闭保持的TCP连接状态。
- 长连接和短连接操作过程
短连接:建立连接——数据传输——关闭连接…建立连接——数据传输——关闭连接
长连接:建立连接——数据传输…(保持连接)…数据传输——关闭连接
- 长连接和短连接的优缺点
长连接可以省去较多的TCP建立和关闭的操作,减少资源的浪费,节约用户访问所消耗的时间。对于频繁请求资源的网站来说,较适用长连接。不过这里存在一个问题,存活功能的探测周期太长,还有就是它只是探测TCP连接的存活,属于比较斯文的做法,遇到恶意的连接时,保活功能就不够使了。
在长连接的应用场景下,client端一般不会主动关闭它们之间的连接,client与server之间的连接如果一直不关闭的话,会存在一个问题,随着客户端连接越来越多,server早晚有扛不住的时候,这时候server端需要采取一些策略,如关闭一些长时间没有读写事件发生的连接,这样可以避免一些恶意连接导致server端服务受损;如果条件再允许就可以以客户端机器为颗粒度,限制每个客户端的最大长连接数,这样可以完全避免某个蛋疼的客户端连累后端服务。
短连接对于服务器来说管理较为简单,存在的连接都是有用的连接,不需要额外的控制手段。但如果客户请求频繁,将在TCP的建立和关闭操作上浪费时间和带宽。
长连接多用于操作频繁,点对点的通讯,而且连接数不能太多情况。如数据库的连接用长连接,如果用短连接频繁的通信会造成socket错误,而且频繁的socket创建也是对资源的浪费。而像Web网站的http服务一般都用短链接,因为长连接对于服务端来说会耗费一定的资源,而像Web网站这么频繁的成千上万甚至上亿客户端的连接用短连接会更省一些资源,如果用长连接,而且同时有成千上万的用户,如果每个用户都占用一个连接的话,那可想而知吧。所以并发量大,但每个用户无需频繁操作情况下需用短连好。
长连接和短连接的产生在于client和server采取的关闭策略,具体的应用场景采用具体的策略,没有十全十美的选择,只有合适的选择。
3.3 企业带宽和家用带宽的区别?
带宽分为上行和下行,家用带宽的上下行不是对等,而且下行远远大于上行,会导致上传速度超级慢。而企业式的带宽,往往都是上下行都是对等,且高峰时期,家庭式的可能网速会减慢,但是企业的都是专线,不会减,但是企业级的费用比较高。
企业带宽计费方式一般为去峰值和95 线两种,现在也有不同的计费方式,大同小异而已,都比较高。

3.4 pv、uv、qps、active connection
PV:页面访问量
- 按日计算全站的访问量
- 一般指静态的页面,如首页、列表页、详情页
- 大型网站一般在
1-10亿 - 网站一般分为三级分类:首页、列表页、详情页
UV:用户访问
- 独立
IP地址 - 用于表现网站的活跃度
- 一般波动幅度不会很大且有相关性
active connection:活动连接数
- 访问网站页面时请求页面资源而建立的连接数
- 这里就要考虑是否使用持久连接机制
- 浏览器对用一个域名最大有
5-6个并发连接,所有可以使用多域名加速网站 - 想要查看网站的活动连接数需要在负载均衡层查看,通过
ss -s命令查看
QPS:每秒的请求数量
- 请求一般为新的(
NEW)请求,即新建立的请求 - 一般日均
2亿PV的网站,active connection为100w左右,QPS为1-2w左右



