使用 Python 代码来画流程图
Diagrams 工具可以使我们使用 Python 代码绘制、生成系统架构图。它的诞生是为了那些没有任何设计工具的新系统架构设计提供原型,我们可以描述或可视化现有的系统架构图。Diagrams 目前支持主要的主要图形包括:AWS,Azure,Kubernetes,阿里云,Oracle 等云平台。与此同时,它还支持本地节点、SaaS 和主要的编程框架和语言。咳咳咳,还有 Go 语言版本的 go-diagrams 工具,有兴趣的话,可以看看。
1. 安装说明
安装方式有可能发生变化,如有问题可以参阅官方文档对应的安装说明!
在 Diagrams 工具画图的时候,需要注意的是其不支持老版本,只支持 Python3.6 或更高版本。如果你安装之后无法使用的话,请先检查你的 Python 版本是为正确。并且,其使用 Graphviz 来完成画图表的功能,所以我们需要事先安装 Graphviz 工具才可以画图不然会报错。
- [1] 安装 Graphviz 工具
# Mac
$ brew install graphviz
# Ubuntu
$ apt install -y graphviz
- [2] 安装 Diagrams 工具
# using pip
$ pip install diagrams
$ pip3 install diagrams
# using pipenv
$ pipenv install diagrams
# using poetry
$ poetry add diagrams
2. 简单使用
介绍新手一开始使用工具时的操作步骤和方法!
2.1 图 - Diagrams
Diagram - Diagram 工具的第一个核心对象就是图
- 我们使用
Diagram类创建一个对应的上下文,开始构建、画图。
| 编号 | Diagram 类参数 | 对应功能 | 示例代码 |
|---|---|---|---|
| 1 | filename |
指定文件名称 | filename="my_diagram" |
| 2 | outformat |
指定图片生成格式 | outformat="jpg" |
| 3 | show |
运行后是否自动显示 | show=False |
| 4 | graph_attr |
自定义 Graphviz 属性 | graph_attr=graph_attr |
| 5 | node_attr |
自定义 Node 属性 | node_attr=node_attr |
| 6 | edge_attr |
自定义 Edge 属性 | edge_attr=edge_attr |
from diagrams import Diagram
from diagrams.aws.compute import EC2
with Diagram("Simple Diagram", filename="my_diagram", outformat="jpg"):
EC2("web")
from diagrams import Diagram
from diagrams.aws.compute import EC2
graph_attr = {
"fontsize": "45",
"bgcolor": "transparent"
}
with Diagram("Simple Diagram", show=False, graph_attr=graph_attr):
EC2("web")
- 然后保存并执行之后,就会在当前目录下面生成一个同名的
png图片,即代码生成的流程图。
# diagram.png
$ python diagram.py
2.2 组件 - Nodes
Nodes - Diagram 工具的第二个核心对象就是节点(系统组件)
- [1] 节点对象由三部分组成,分别是
provider、resource type和name。- EC2 是 aws 提供程序提供的计算资源类型的节点
# aws resources
from diagrams.aws.compute import ECS, Lambda
from diagrams.aws.database import RDS, ElastiCache
from diagrams.aws.network import ELB, Route53, VPC
...
# azure resources
from diagrams.azure.compute import FunctionApps
from diagrams.azure.storage import BlobStorage
...
- [2] 数据流向使我们画图时常常会使用到的功能。
-- 连接节点没有方向>>- 节点从左到右连接<<- 节点从右到左连接
| 编号 | Diagram 类参数 | 对应功能 | 示例代码 |
|---|---|---|---|
| 1 | direction |
节点图形排列顺序(TB/BT/LR/RL) | direction="TB" |
from diagrams import Diagram
from diagrams.aws.compute import EC2
from diagrams.aws.database import RDS
from diagrams.aws.network import ELB
from diagrams.aws.storage import S3
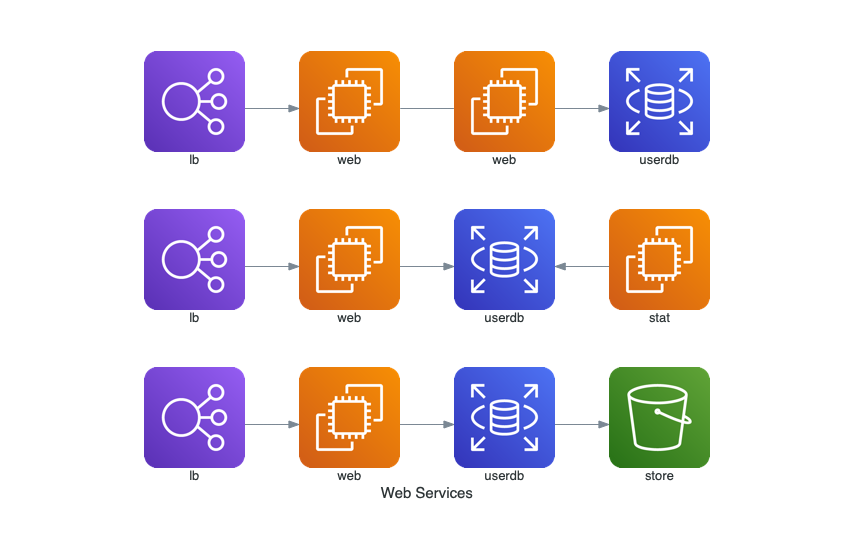
with Diagram("Web Services", show=False):
ELB("lb") >> EC2("web") >> RDS("userdb") >> S3("store")
ELB("lb") >> EC2("web") >> RDS("userdb") << EC2("stat")
(ELB("lb") >> EC2("web")) - EC2("web") >> RDS("userdb")
from diagrams import Diagram
from diagrams.aws.compute import EC2
from diagrams.aws.database import RDS
from diagrams.aws.network import ELB
with Diagram("Workers", show=False, direction="TB"):
lb = ELB("lb")
db = RDS("events")
lb >> EC2("worker1") >> db
lb >> EC2("worker2") >> db
lb >> EC2("worker3") >> db
lb >> EC2("worker4") >> db
lb >> EC2("worker5") >> db
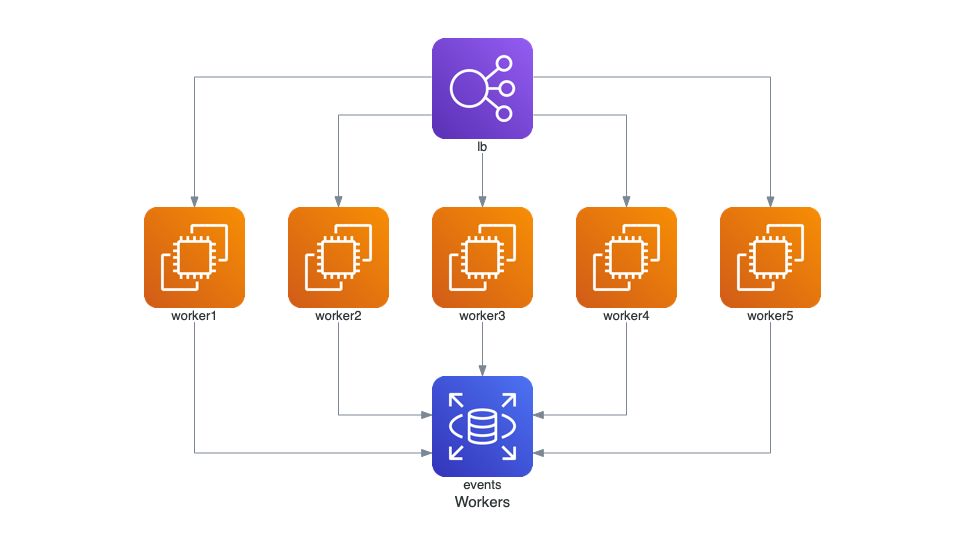
from diagrams import Diagram
from diagrams.aws.compute import EC2
from diagrams.aws.database import RDS
from diagrams.aws.network import ELB
with Diagram("Grouped Workers", show=False, direction="TB"):
ELB("lb") >> [EC2("worker1"),
EC2("worker2"),
EC2("worker3"),
EC2("worker4"),
EC2("worker5")] >> RDS("events")
2.3 Clusters
Cluster 允许您将节点分组或集群在一个独立的组中
- 可以使用
cluster类来创建一个集群上下文,还可以将集群中的节点连接到集群之外的其他节点。
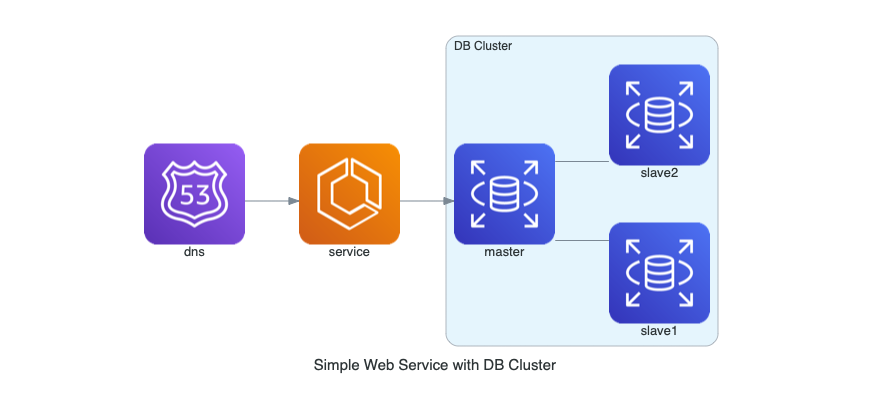
from diagrams import Cluster, Diagram
from diagrams.aws.compute import ECS
from diagrams.aws.database import RDS
from diagrams.aws.network import Route53
with Diagram("Simple Web Service with DB Cluster", show=False):
dns = Route53("dns")
web = ECS("service")
with Cluster("DB Cluster"):
db_master = RDS("master")
db_master - [RDS("slave1"),
RDS("slave2")]
dns >> web >> db_master
- 套叠集群
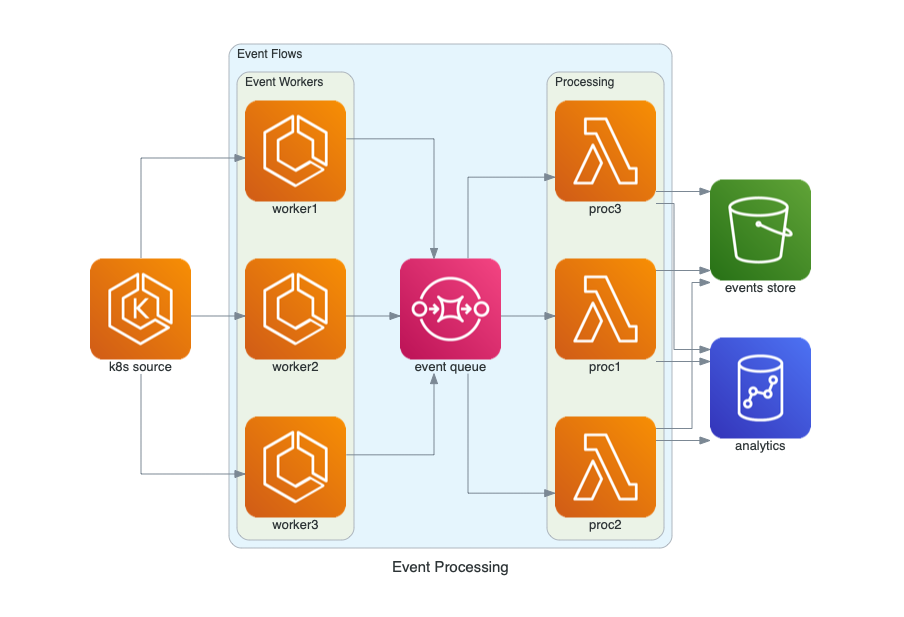
from diagrams import Cluster, Diagram
from diagrams.aws.compute import ECS, EKS, Lambda
from diagrams.aws.database import Redshift
from diagrams.aws.integration import SQS
from diagrams.aws.storage import S3
with Diagram("Event Processing", show=False):
source = EKS("k8s source")
with Cluster("Event Flows"):
with Cluster("Event Workers"):
workers = [ECS("worker1"),
ECS("worker2"),
ECS("worker3")]
queue = SQS("event queue")
with Cluster("Processing"):
handlers = [Lambda("proc1"),
Lambda("proc2"),
Lambda("proc3")]
store = S3("events store")
dw = Redshift("analytics")
source >> workers >> queue >> handlers
handlers >> store
handlers >> dw
2.4 Edge
Edge - 线表示节点之间的关系
Edge对象包含三个属性:label、color和style
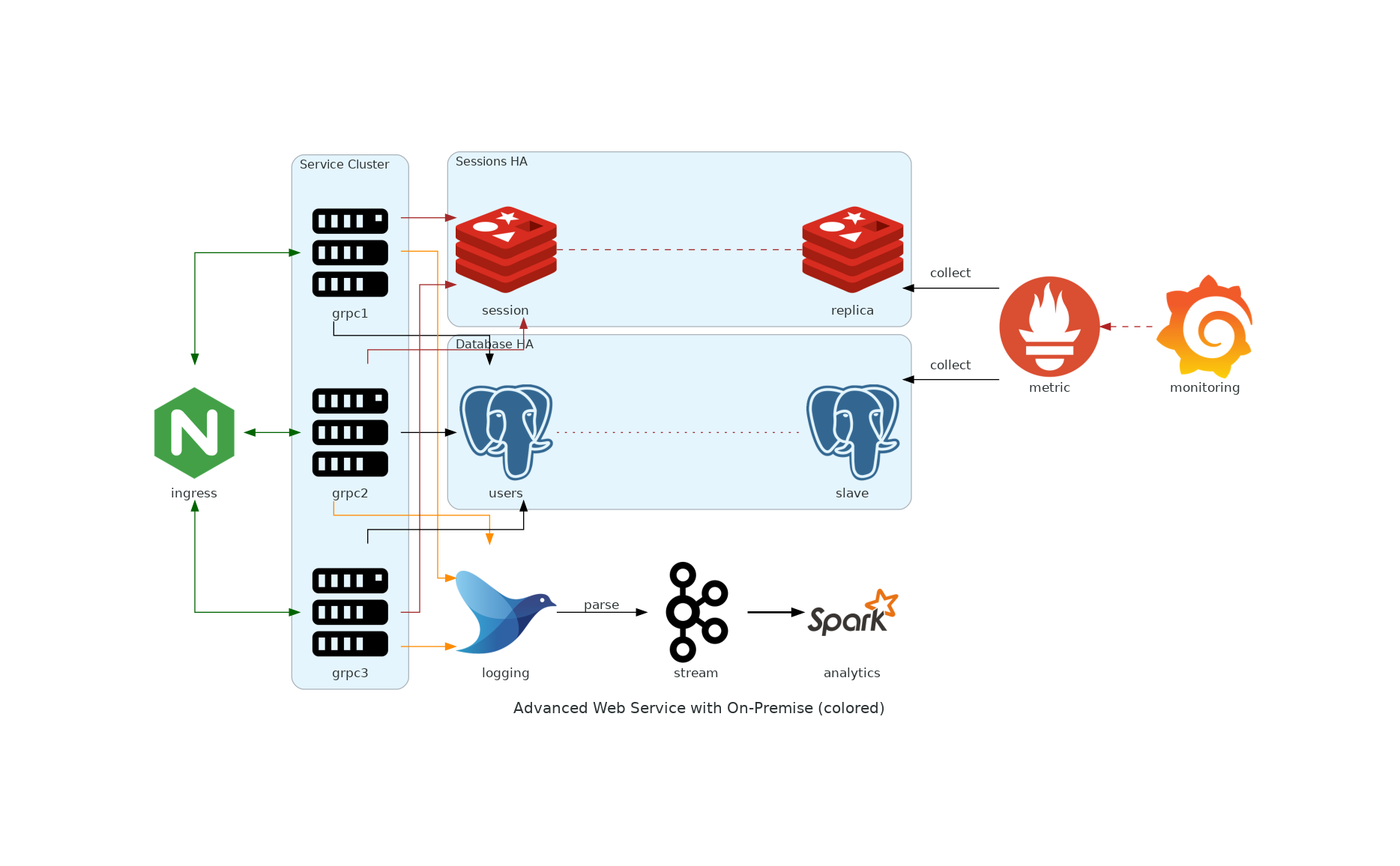
from diagrams import Cluster, Diagram, Edge
from diagrams.onprem.analytics import Spark
from diagrams.onprem.compute import Server
from diagrams.onprem.database import PostgreSQL
from diagrams.onprem.inmemory import Redis
from diagrams.onprem.logging import Fluentd
from diagrams.onprem.monitoring import Grafana, Prometheus
from diagrams.onprem.network import Nginx
from diagrams.onprem.queue import Kafka
with Diagram(name="Advanced Web Service with On-Premise (colored)", show=False):
ingress = Nginx("ingress")
metrics = Prometheus("metric")
metrics << Edge(color="firebrick", style="dashed") << Grafana("monitoring")
with Cluster("Service Cluster"):
grpcsvc = [
Server("grpc1"),
Server("grpc2"),
Server("grpc3")]
with Cluster("Sessions HA"):
master = Redis("session")
master - Edge(color="brown", style="dashed") - Redis("replica") << Edge(label="collect") << metrics
grpcsvc >> Edge(color="brown") >> master
with Cluster("Database HA"):
master = PostgreSQL("users")
master - Edge(color="brown", style="dotted") - PostgreSQL("slave") << Edge(label="collect") << metrics
grpcsvc >> Edge(color="black") >> master
aggregator = Fluentd("logging")
aggregator >> Edge(label="parse") >> Kafka("stream") >> Edge(color="black", style="bold") >> Spark("analytics")
ingress >> Edge(color="darkgreen") << grpcsvc >> Edge(color="darkorange") >> aggregator
3. 示例展示
上手画图很简单,基本就是套示例代码就可以了。
基本看了官方对应的示例,就可以画图了,找个大概相似的情况,改吧改吧就可以了。比用鼠标点击的方式画图来得快,而且也相对来说好看点(不用担心划线、走线、错位之类的问题)。但是高级用法的话,还是应该看看 Guides 和 Nodes 部分的文档。科科,当然也是有 Bug 存在的,遇到的时候可以提交 Issus,一起来改进。
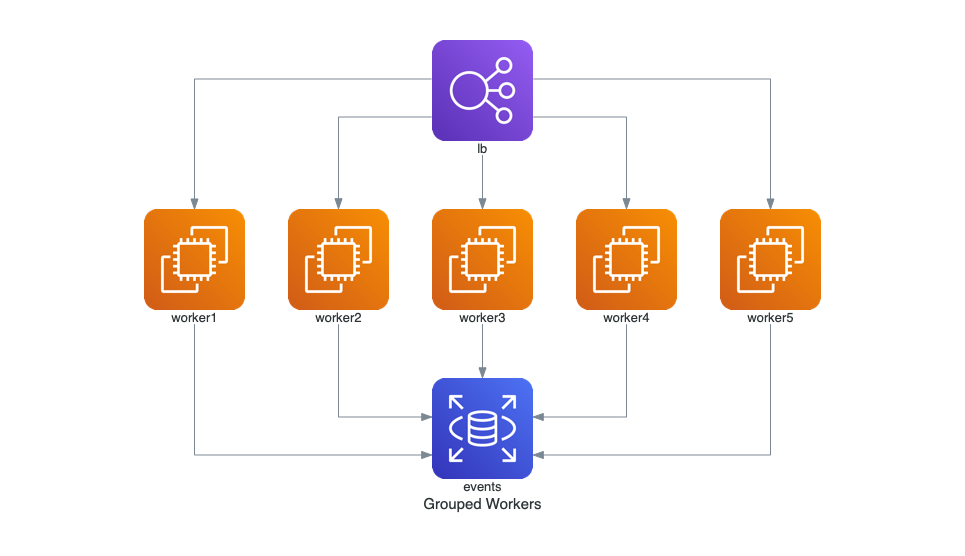
- [1] Grouped Workers
from diagrams import Diagram
from diagrams.aws.compute import EC2
from diagrams.aws.database import RDS
from diagrams.aws.network import ELB
with Diagram("Grouped Workers", show=False, direction="TB"):
ELB("lb") >> [EC2("worker1"),
EC2("worker2"),
EC2("worker3"),
EC2("worker4"),
EC2("worker5")] >> RDS("events")
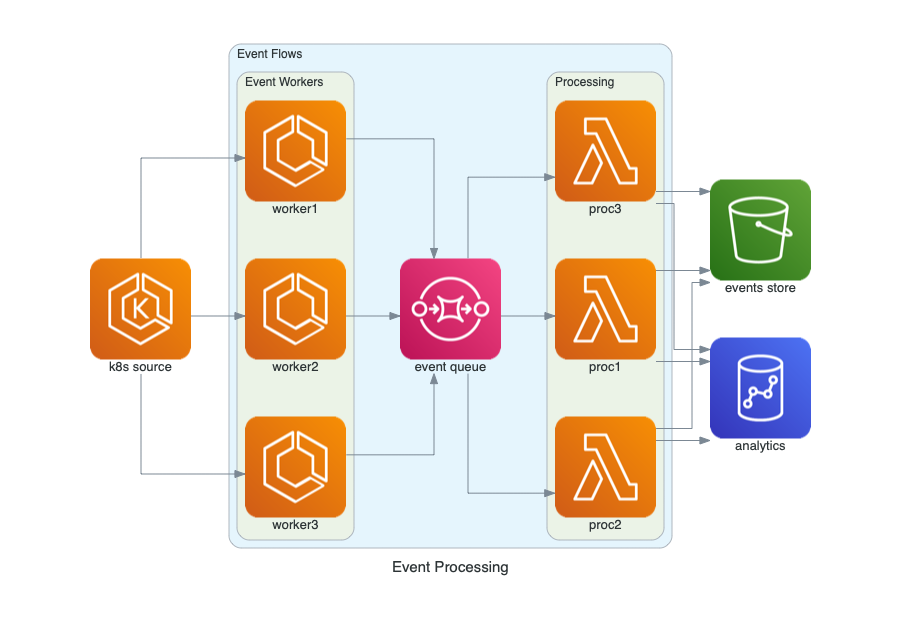
- [2] Event Processing
from diagrams import Cluster, Diagram
from diagrams.aws.compute import ECS, EKS, Lambda
from diagrams.aws.database import Redshift
from diagrams.aws.integration import SQS
from diagrams.aws.storage import S3
with Diagram("Event Processing", show=False):
source = EKS("k8s source")
with Cluster("Event Flows"):
with Cluster("Event Workers"):
workers = [ECS("worker1"),
ECS("worker2"),
ECS("worker3")]
queue = SQS("event queue")
with Cluster("Processing"):
handlers = [Lambda("proc1"),
Lambda("proc2"),
Lambda("proc3")]
store = S3("events store")
dw = Redshift("analytics")
source >> workers >> queue >> handlers
handlers >> store
handlers >> dw
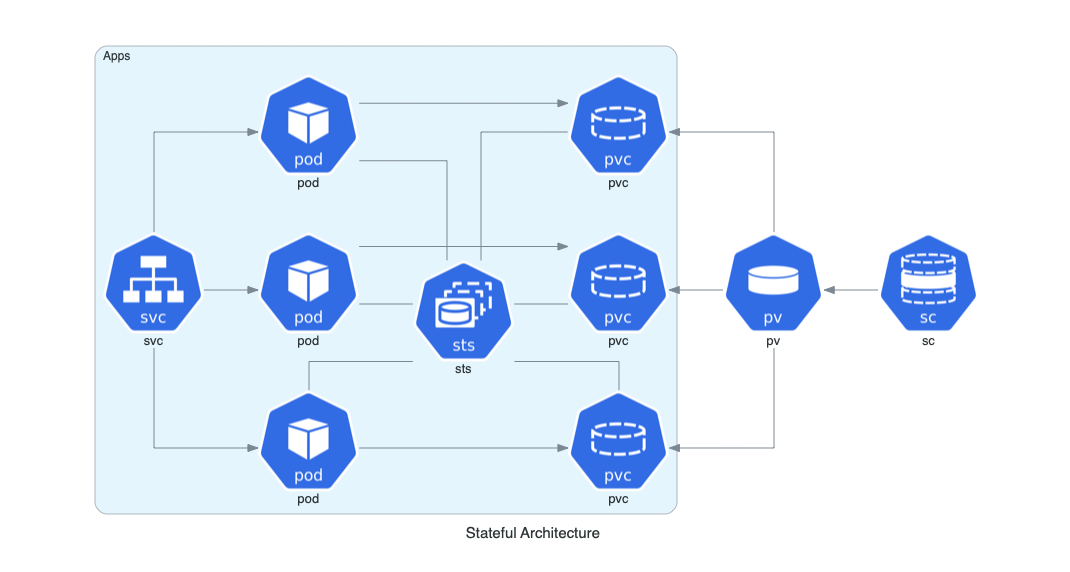
- [3] Stateful Architecture
from diagrams import Cluster, Diagram
from diagrams.k8s.compute import Pod, StatefulSet
from diagrams.k8s.network import Service
from diagrams.k8s.storage import PV, PVC, StorageClass
with Diagram("Stateful Architecture", show=False):
with Cluster("Apps"):
svc = Service("svc")
sts = StatefulSet("sts")
apps = []
for _ in range(3):
pod = Pod("pod")
pvc = PVC("pvc")
pod - sts - pvc
apps.append(svc >> pod >> pvc)
apps << PV("pv") << StorageClass("sc")
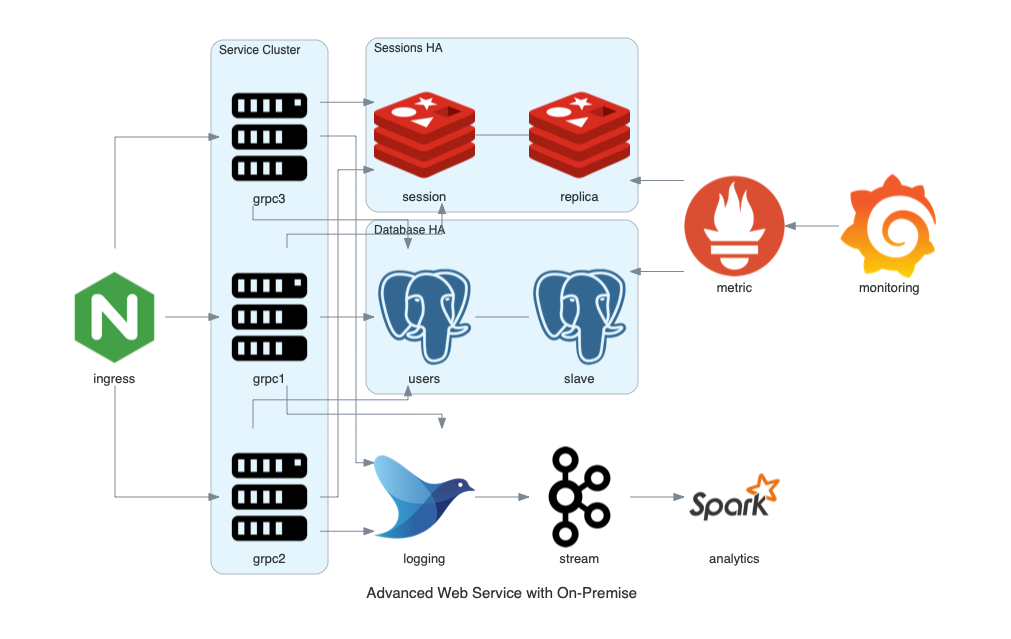
- [4] Advanced Web Service
from diagrams import Cluster, Diagram
from diagrams.onprem.analytics import Spark
from diagrams.onprem.compute import Server
from diagrams.onprem.database import PostgreSQL
from diagrams.onprem.inmemory import Redis
from diagrams.onprem.logging import Fluentd
from diagrams.onprem.monitoring import Grafana, Prometheus
from diagrams.onprem.network import Nginx
from diagrams.onprem.queue import Kafka
with Diagram("Advanced Web Service with On-Premise", show=False):
ingress = Nginx("ingress")
metrics = Prometheus("metric")
metrics << Grafana("monitoring")
with Cluster("Service Cluster"):
grpcsvc = [
Server("grpc1"),
Server("grpc2"),
Server("grpc3")]
with Cluster("Sessions HA"):
master = Redis("session")
master - Redis("replica") << metrics
grpcsvc >> master
with Cluster("Database HA"):
master = PostgreSQL("users")
master - PostgreSQL("slave") << metrics
grpcsvc >> master
aggregator = Fluentd("logging")
aggregator >> Kafka("stream") >> Spark("analytics")
ingress >> grpcsvc >> aggregator