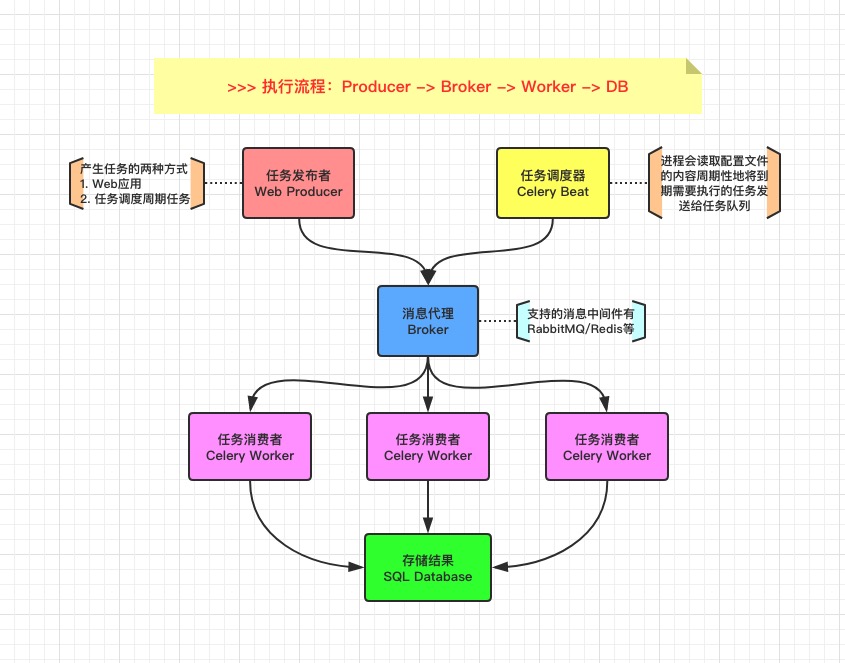
在使用
PostgreSQL数据库在做写入操作时,对数据文件做的任何修改信息,首先会写入WAL日志(预写日志),然后才会对数据文件做物理修改。当数据库服务器掉重启时,PostgreSQL数据库在启动时会优先读取WAL日志,对数据文件进行恢复。因此,从理论上讲,如果我们有一个数据库的基础备份(也称为全备),再配合WAL日志,是可以将数据库恢复到过去的任意时间点上。

1. 安装压缩工具
这里使用的压缩工具是
zstd,因为其无损压缩且更快。
- [1] Ubutun
# Ubutun
$ sudo apt install zstd
- [2] CentOS
# CentOS
$ sudo yum install zstd
2. 修改配置文件
所谓 WAL 日志归档,其实就是把在线的 WAL 日志备份出来。
- [主] 数据库路径 => /data/app/pg_data/
- [备] 数据库路径 => /data/pg_wal_backup/
有一点很重要:当且仅当归档命令成功时,它才返回零退出。在得到一个零值结果之后,PostgreSQL 将假设该文件已经成功归档, 因此它稍后将被删除或者被新的数据覆盖。但是,一个非零值告诉 PostgreSQL 该文件没有被归档; 因此它会周期性的重试直到成功。
同时,归档命令通常应该被设计成拒绝覆盖已经存在的归档文件。这是一个非常重要的安全特性, 可以在管理员操作失误(比如把两个不同的服务器的输出发送到同一个归档目录)的时候保持你的归档的完整性。归档命令的速度并不要紧,只要它能跟上你的服务器生成 WAL 数据的平均速度即可。即使归档进程稍微落后,正常的操作也会继续进行。 如果归档进程慢很多,就会增加灾难发生的时候丢失的数据量。这同时也意味着 pg_wal/ 目录包含大量未归档的段文件, 并且可能最后超出了可用磁盘空间。
请注意尽管 WAL 归档允许你恢复任何对你的 PostgreSQL 数据库中数据所做的修改,但它不会恢复对配置文件的修改(即postgresql.conf、pg_hba.conf 和 pg_ident.conf),因为这些文件都是手工编辑的,而不是通过 SQL 操作来编辑的,所以你可能会需要把你的配置文件放在一个日常文件系统备份过程可处理的位置。
- [1] 全量备份数据库
# 主数据库目录
/data/app/pg_data/
# 创建备份目录
mkdir -pv /data/pg_wal_backup/
mkdir -pv /data/pg_wal_backup/{basebackup, wal}
# 进入备份目录做一次基础备份
# 用于获取正在运行的PostgreSQL数据库集群的基本备份
# 不会影响数据库的其他客户端,可用于时间点恢复或流复制备用服务器的起点
$ cd /data/pg_wal_backup/basebackup
$ sudo /usr/lib/postgresql/10/bin/pg_basebackup -U postgres -h 127.0.0.1 -p 5432 -D ./
- [2] 修改数据库配置文件
# [数据库默认配置文件] => 容器映射出来的数据库地址
# [archive_mode] => 参数修改后需重启数据库才生效,而archive_command则不需要
# [archive_command] => WAL日志备份的Unix命令或者脚本用于将日志拷贝到其他的地方
# [archive_command] => 需要注意备份的目录权限需要设置为数据库启动的用户权限
# [备份不使用压缩工具] => archive_command = 'cp %p /data/pg_wal_backup/wal/%f'
$ sudo vim /data/app/pg_data/postgresql.conf
wal_level = replica # 需要将日志级别设置为replica或更高级别; 可使用默认值
archive_mode = on # 打开归档备份
archive_command = '/usr/local/bin/archive_wal.sh %f %p /data/pg_wal_backup/wal'
# [本地备份] 使用cp命令
archive_command = 'cp %p /data/pg_wal_backup/wal/%f'
archive_command = 'test ! -f /data/pg_wal_backup/wal/%f && cp %p /data/pg_wal_backup/wal/%f'
# [本地备份] 示例说明
archive_command = 'cp /data/app/pg_data/pg_wal/0xxx065 /data/pg_wal_backup/wal/0xxx065'
# [远程备份] 使用scp命令
archive_command ='scp %p [email protected]:/data/pg_wal_backup/wal/%f'
# [远程备份] 示例说明
archive_command = 'scp /data/app/pg_data/pg_wal/0xxx065 [email protected]:/data/pg_wal_backup/wal/0xxx065'
- [3] 添加 WAL 备份脚本
# 这里我们对备份机制做了一点点优化
# %f => 是要被归档的日志文件的文件名
# %p => 是要被归档的日志文件的路径及名称
# /usr/local/bin/archive_wal.sh %f %p /data/pg_wal_backup/wal
$ sudo vim /usr/local/bin/archive_wal.sh
#!/usr/bin/env bash
EXIT_CODE=0
ARCHIVE_FILE=${1} # %f
ARCHIVE_DIR=${2} # %p
BACKUP_PATH=${3} # /data/pg_wal_backup/wal
if [[ -d "${BACKUP_PATH}" ]]; then
command -v zstd > /dev/null 2>&1
if [[ $? -gt 0 ]]; then
gzip < ${ARCHIVE_DIR} > "${BACKUP_PATH}/${ARCHIVE_FILE}"
# restore_command => gunzip < ${BACKUP_PATH}/${ARCHIVE_FILE} > $ARCHIVE_DIR
else
zstd -f -q -o "${BACKUP_PATH}/${ARCHIVE_FILE}" ${ARCHIVE_DIR}
# restore_command => zstd -d -q -o $ARCHIVE_DIR ${BACKUP_PATH}/${ARCHIVE_FILE}
fi
EXIT_CODE=$?
fi
exit ${EXIT_CODE}
3. 自动归档备份
所有的操作都是为了一旦数据有问题时进行回退或回滚使用 => 命令参数手册
# 配置完成之后,首先要做的就是重启数据库
# 我们这里基本都是使用Supervisor工具进行数据库管理的
$ sudo supervisorctl restarrt app-postgres
# 修改wal_level和archive_mode参数都需要重新启动数据库才可以生效
# 而修改archive_command参数不需要重启,只需要reload数据库配置即可
postgres=# SELECT pg_reload_conf();
postgres=# show archive_command;
# 定时任务 => 创建用于执行还原的命名点
# 默认情况下仅限于超级用户,但可以授予其他用户EXECUTE以运行该功能
$ sudo crontab -l
0 * * * * bash -c "psql -U postgres -h 127.0.0.1 -p 5432 -c
\"select pg_create_restore_point('$(date +\"\%Y\%m\%d\%H\%M\")');\""
# 正常创建恢复点之后,数据库的log文件定时会显示如下内容
# 需要注意的是,Wal的备份目录会跟随数据增长而增加Wal文件
$ sudo grep CRON /var/log/syslog
2019-06-11 17:00:01.624 CST [7454] LOG: restore point "201906111700" created at 85/8C84AF80
2019-06-11 17:00:01.624 CST [7454] STATEMENT: select pg_create_restore_point('201906111700');
4. 触发归档情况
建立归档后,什么情况下会触发归档?
- [方法一] 手动切换 WAL 日志
# PostgreSQL提供pg_switch_xlog()函数可以手工切换WAL日志
# 执行pg_switch_xlog()后,WAL会切换到新的日志,这时会将老的WAL日志归档
-- 手动归档
Type "help" for help.
postgres=# select pg_switch_xlog();
pg_switch_xlog
----------------
0/87000000
(1 row)
- [方法二] WAL 日志写满后触发归档
我们知道 WAL 日志被写满后会触发归档,官方文档在说明该配置参数 archive_command 的时候,第一句说就说明了这点。WAL 日志文件的默认大小为 16MB,这个值可以在编译 PostgreSQL 时通过参数 "–with-wal-segsize" 参数更改,编译后不能修改。
- [方法三] 设置 archive_timeout 参数
另外,可以设置 PostgreSQL 数据库的 archive 超时参数 archive_timeout。假如设置 archive_timeout=60,那么每 60s 会触发一次 WAL 日志切换,同时触发日志归档。这里有个隐含的假设,就是当前 WAL 日志中仍有未归档的 WAL 日志内容。
尽量不要把 archive_timeout 设置的很小,如果设置的很小,它会膨胀你的归档存储。因为,你强制归档的日志,即使没有写满,也会是默认的 16M 大小(假设wal日志写满的大小为16M的话)。
5. 数据恢复方法
实现目标:手动创建归档备份和恢复点都是为了异常时恢复到指定时间点
- [主] 数据库路径 => /data/app/pg_data/
- [备] 数据库路径 => /data/pg_wal_backup/
如果最坏的情况发生了,你需要从你的备份进行恢复,大致流程如下:
- 如果服务器仍在运行,停止它。
- 如果你具有足够的空间,将整个集簇数据目录和表空间复制到一个临时位置,稍后你将用到它们。
- 移除所有位于集簇数据目录和正在使用的表空间根目录下的文件和子目录。
- 在集簇数据目录中创建一个 recovery.conf 恢复命令文件
- 启动服务器,服务器将会进入到恢复模式并且进而根据需要读取归档 WAL 文件。
- 检查数据库的内容来确保你已经恢复到了期望的状态。
- [初始化] 数据库全量备份和配置
# 1.开启WAL归档
$ vim /data/app/pg_data/postgresql.conf
wal_level='replica' # 至少设置为replica模式才可还原数据库
archive_mode='on' # 开启WAL归档
archive_command='cp %p /data/pg_wal_backup/wal/%f'
# 2.全量基础备份
$ /usr/lib/postgresql/10/bin/pg_basebackup -U postgres -D /data/pg_wal_backup/basebackup
# 3.数据初始化
$ psql -U postgres -h 127.0.0.1 -p 5432 -d app
> app=# create table test01(id int primary key,name varchar(20));
> app=# insert into test01 values(1,'a'), (2,'b'), (3,'c');
List of relations
Schema | Name | Type | Owner
--------+--------+-------+----------
public | test01 | table | postgres
(1 row)
# 4.备份完之后做一次WAL切换,保证最新的WAL日志归档到归档目录
$ psql -U postgres -h 127.0.0.1 -p 5432 -d app
> app=# select pg_switch_wal();
- [创建] 创建还原点并删除数据
# 1.test01表目前有三条数据
$ psql -U postgres -h 127.0.0.1 -p 5432 -d app
> app=# select * from test01;
id | name
----+------
1 | a
2 | b
3 | c
(3 rows)
# 2.创建一个还原点
$ bash -c "psql -U postgres -h 127.0.0.1 -p 5432 -c \"select pg_create_restore_point('$(date +\"\%Y\%m\%d\%H\%M\")');\""
2019-06-12 23:08:30.317 CST [4498] LOG: restore point "201906122308" created at 0/A0004C8
2019-06-12 23:08:30.317 CST [4498] STATEMENT: select pg_create_restore_point('201906122308');
pg_create_restore_point
-------------------------
0/A0004C8
(1 row)
# 3.误操作将数据删除
$ psql -U postgres -h 127.0.0.1 -p 5432 -d app
> app=# delete from test01;
DELETE 3
# 4.记录下现在时间和误操作时间的大致间隔
$ psql -U postgres -h 127.0.0.1 -p 5432 -d app
> app=# select current_timestamp;
current_timestamp
-------------------------------
2019-06-12 22:54:55.794813+08
# 5.顺便归个档
# 由于WAL文件是写满16MB才会进行归档,测试阶段可能写入会非常少
# 可以在执行完基础备份之后,手动进行一次WAL切换,顺便归个档
$ psql -U postgres -h 127.0.0.1 -p 5432 -d app
> app=# select pg_switch_wal();
pg_switch_wal
---------------
0/A0005N8
(1 row)
- [恢复] 恢复到某一时间点
# =.= 数据恢复
# 思路是利用最新的全量备份+wal日志恢复数据
$ ls -lh /data/pg_wal_backup/
drwx------ 19 app app 29 Dec 16 15:33 basebackup/ # 全量包
drwx------ 19 app app 29 Dec 16 15:34 pg_dump/ # 故障时全量包
drwx------ 2 app app 786 Dec 16 15:26 wal/ # wal备份文件
# 1.全量备份当前数据库
$ /usr/lib/postgresql/10/bin/pg_dump \
-U postgres -p 5432 -d draft -Z9 \
-f /data/pg_wal_backup/pg_dump/app_`date +%Y%m%d%H%M%S`.sql.gz
# 2.停止当前数据库
$ /usr/lib/postgresql/10/bin/pg_ctl stop -D /data/app/pg_data/ -h 127.0.0.1 -p 5432 -m fast
# 3.根据之前介绍的归档情况会存在缓存没有写入WAL备份的情况(默认有5个)
$ ls -lh /data/app/pg_data/pg_wal
-rw------- 1 999 ci 16777216 Jan 22 18:52 000000010000000000000010
-rw------- 1 999 ci 16777216 Jan 21 14:49 000000010000000000000011
-rw------- 1 999 ci 16777216 Jan 22 11:53 000000010000000000000012
-rw------- 1 999 ci 16777216 Jan 22 14:26 000000010000000000000013
-rw------- 1 999 ci 16777216 Jan 22 18:36 000000010000000000000014
drwx------ 2 999 ci 4096 Jan 22 18:42 archive_status/
# 4.需要将缓存中WAL文件进行归档
cp /data/app/pg_data/pg_wal/000000010000000000000010 /data/pg_wal_backup/wal/000000010000000000000010
cp /data/app/pg_data/pg_wal/000000010000000000000011 /data/pg_wal_backup/wal/000000010000000000000011
cp /data/app/pg_data/pg_wal/000000010000000000000012 /data/pg_wal_backup/wal/000000010000000000000012
......
# 5.删除当前数据库并将备份数据导入
$ rm -rf /data/app/pg_data/
$ cp -r /data/pg_wal_backup/basebackup/* /data/app/pg_data/
$ cp -r /data/pg_wal_backup/wal/* /data/app/pg_data/pg_wal
$ chown -R postgres:postgres /data/app/pg_data/
$ chmod -R 700 /data/app/pg_data/
# 6.将最新的备份恢复到数据目录
$ cp /usr/share/postgresql/10/recovery.conf.sample /data/app/pg_data/recovery.conf
$ chmod 0600 /data/app/pg_data/recovery.conf
# 7.配置恢复配置文件
$ vim /data/app/pg_data/recovery.conf
restore_command='cp /data/app/pg_data/pg_wal/%f %p'
recovery_target_name='2019-12-12 12:12:00'
recovery_target_timeline='latest'
# 8.修改postgresql.conf配置文件将wal备份停止
$ vim /data/app/pg_data/postgresql.conf
wal_level='replica'
archive_mode='off'
archive_command=''
# 9.启动数据,进入恢复状态,观察日志,如下所示
$ /usr/lib/postgresql/10/bin/pg_ctl -o "-p 5432" start -D /data/app/pg_data
waiting for server to start....2019-06-12 23:44:28.034 CST [4607] LOG: listening on IPv4 address "127.0.0.1", port 5432
2019-06-12 23:44:28.035 CST [4607] LOG: could not bind IPv6 address "::1": Cannot assign requested address
2019-06-12 23:44:28.035 CST [4607] HINT: Is another postmaster already running on port 5432? If not, wait a few seconds and retry.
2019-06-12 23:44:28.041 CST [4607] LOG: listening on Unix socket "/var/run/postgresql/.s.PGSQL.5432"
2019-06-12 23:44:28.060 CST [4608] LOG: database system was interrupted; last known up at 2019-06-12 22:26:05 CST
2019-06-12 23:44:28.106 CST [4608] LOG: starting point-in-time recovery to "201912121200"
2019-06-12 23:44:28.135 CST [4608] LOG: restored log file "000000010000000000000003" from archive
2019-06-12 23:44:28.492 CST [4608] LOG: redo starts at 0/3000060
2019-06-12 23:44:28.493 CST [4608] LOG: consistent recovery state reached at 0/3000130
2019-06-12 23:44:28.494 CST [4607] LOG: database system is ready to accept read only connections
done
server started
2019-06-12 23:44:28.530 CST [4608] LOG: restored log file "000000010000000000000004" from archive
2019-06-12 23:44:28.910 CST [4608] LOG: restored log file "000000010000000000000005" from archive
2019-06-12 23:44:29.304 CST [4608] LOG: restored log file "000000010000000000000006" from archive
2019-06-12 23:44:29.655 CST [4608] LOG: restored log file "000000010000000000000007" from archive
2019-06-12 23:44:30.004 CST [4608] LOG: restored log file "000000010000000000000008" from archive
2019-06-12 23:44:30.334 CST [4608] LOG: restored log file "000000010000000000000009" from archive
2019-06-12 23:44:30.689 CST [4608] LOG: restored log file "00000001000000000000000A" from archive
2019-06-12 23:44:30.863 CST [4608] LOG: recovery stopping at restore point "201912121200", time 2019-12-12 12:12:12.317748+08
2019-06-12 23:44:30.863 CST [4608] LOG: recovery has paused
2019-06-12 23:44:30.863 CST [4608] HINT: Execute pg_wal_replay_resume() to continue.
# 10.重启后,我们对test01表进行查询,看数据是否正常恢复
$ psql -U postgres -h 127.0.0.1 -p 5432 -d app
> app=# select * from test01;
id | name
----+------
1 | a
2 | b
3 | c
# 11.解除暂停状态,将recovery.conf变成了recovery.done文件
# 当然recovery.conf可以移除,避免下次数据重启数据再次恢复到该还原点
$ psql -U postgres -h 127.0.0.1 -p 5432 -d app
> app=# select pg_wal_replay_resume();
2019-12-12 23:49:06.133 CST [4608] LOG: redo done at 0/A000460
2019-12-12 23:49:06.133 CST [4608] LOG: last completed transaction was at log time 2019-12-12 23:06:57.417227+08
2019-12-12 23:49:06.157 CST [4608] LOG: selected new timeline ID: 2
2019-12-12 23:49:06.505 CST [4608] LOG: archive recovery complete
2019-12-12 23:49:06.621 CST [4607] LOG: database system is ready to accept connections
6. 数据库时间线
关于备份和恢复的时间线
- [1] 时间线的引入
为了理解引入时间线的背景,我们来分析一下,如果没有时间线,会有什么问题?先举个将数据库恢复到以前时间点的例子。假设在一个数据库的运行过程中,DBA 在周三 12:00AM 删掉了一个关键的表,但是直到周五中午才发现这个问题。这个时候 DBA 拿出最初的数据库备份,加上存在归档目录的日志文件,将数据库恢复到周三 11:00AM 的时间点,这样就能正常启动和运行。但是,DBA 后来意识到这样恢复是不对的,想恢复到周四 8:00AM 的数据,这时会发现无法做到:因为在数据库不断运行中,会产生与旧的 WAL 文件重名的文件,这些文件进入归档目录时,会覆盖原来的旧日志,导致恢复数据库需要的 WAL 文件丢失。为了避免这种情况,需要区分原始数据库历史生成的 WAL 文件和完成恢复之后继续运行产生的(重名的)新 WAL 文件。
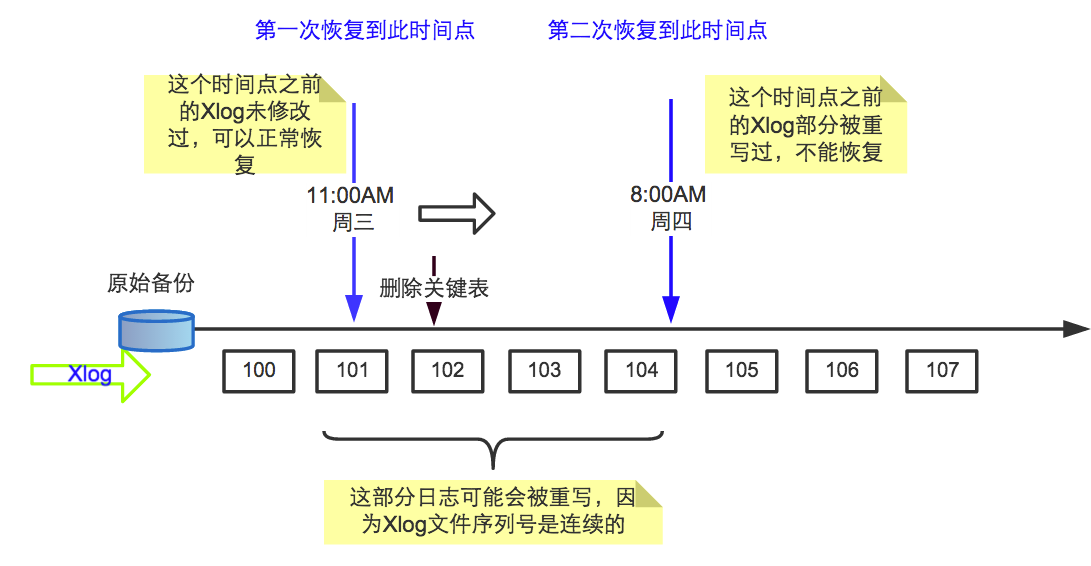
为了解决这个问题,PostgreSQL 引入了时间线的概念。每当归档文件恢复完成后,创建一个新的时间线用来区别新生成的 WAL 记录。WAL 文件名由时间线和日志序号组成,源码实现如下:
#define XLogFileName(fname, tli, log, seg) \
snprintf(fname, XLOG_DATA_FNAME_LEN + 1, "%08X%08X%08X", tli, log, seg)
$ ls -1
00000002.history
00000003.history
00000003000000000000001A
00000003000000000000001B
时间线 ID 号是 WAL 文件名组成之一,因此一个新的时间线不会覆盖由以前的时间线生成的 WAL。如下图所示,每个时间线类似一个分支,在当前时间线的操作不会对其他时间线 WAL 造成影响,有了时间线,我们就可以恢复到之前的任何时间点。
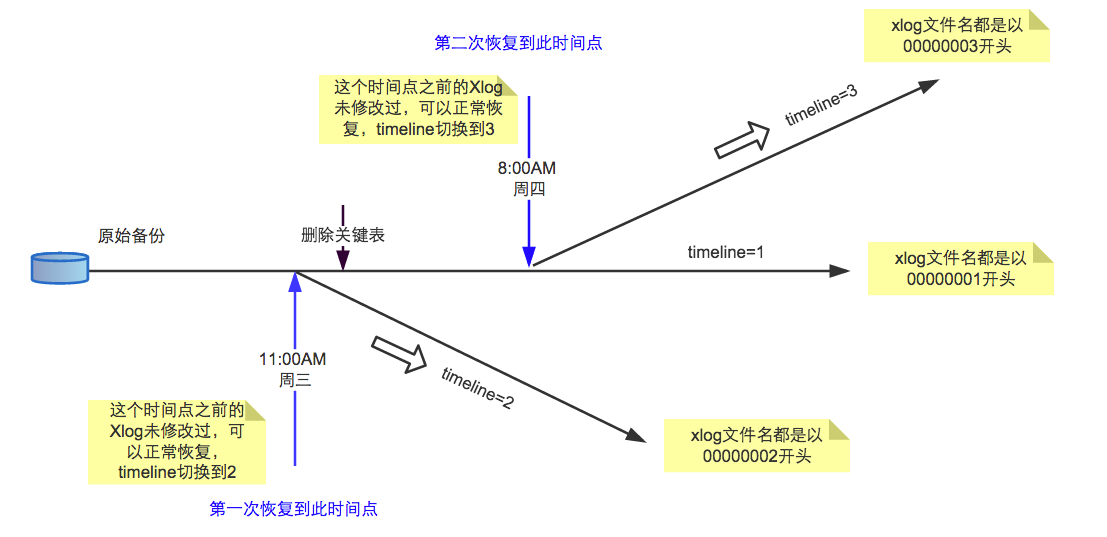
- [2] 新时间线的出现场景
第一种就是:即时恢复(PITR)配置 recovery.conf 文件 => 设置好 recovery.conf 文件后,启动数据库,将会产生新的 timeline,而且会生成一个新的 history 文件。恢复的默认行为是沿着与当前基本备份相同的时间线恢复。如果你想恢复到某些时间线,你需要指定的 recovery.conf 目标时间线 recovery_target_timeline,不能恢复到早于基本备份分支的时间点。
# 从归档目录恢复日志
restore_command = 'cp /mnt/server/archivedir/%f %p'
# 指定归档时间点,如没指定恢复到故障前的最后一完成的事务
recovery_target_time = '2019-07-16 12:00:00'
# 指定归档时间线,latest代表最新的时间线分支,如没指定恢复到故障前的pg_control里面的时间线
recovery_target_timeline = 'latest'
# 打开后将会以备库身份启动,而不是即时恢复
standby_mode = 'off'
第二种就是:standby promote 搭建一个 PG 主备,然后停止主库,在备库机器执行 => 这时候备库将会升为主备,同时产生一个新的 timeline,同样生成一个新的 history 文件。
$ pg_ctl promote –D $PGDATA
- [3] history 文件
每次创建一个新的时间线,PostgreSQL 都会创建一个“时间线历史”文件,文件名类似 .history,它里面的内容是由原时间线 history 文件的内容再追加一条当前时间线切换记录。假设数据库恢复启动后,切换到新的时间线 ID=5,那么文件名就是 00000005.history,该文件记录了自己从什么时间哪个时间线什么原因分出来的,该文件可能含有多行记录,每个记录的内容格式如下所示。
* <parentTLI> <switchpoint> <reason>
* parentTLI ID of the parent timeline
* switchpoint XLogRecPtr of the WAL position where the switch happened
* reason human-readable explanation of why the timeline was changed
$ cat 00000004.history
1 0/140000C8 no recovery target specified
2 0/19000060 no recovery target specified
3 0/1F000090 no recovery target specified
当数据库在从包含多个时间线的归档中恢复时,这些 history 文件允许系统选取正确的 WAL 文件。当然,它也能像 WAL 文件一样被归档到 WAL 归档目录里。历史文件只是很小的文本文件,所以保存它们的代价很小。
当我们在 recovery.conf 指定目标时间线 tli 进行恢复时,程序首先寻找 .history 文件,根据 .history 文件里面记录的时间线分支关系,找到从 pg_control 里面的 startTLI 到 tli 之间的所有时间线对应的日志文件,再进行恢复。
- [4] 时间线的注意要点
将数据库恢复到一个之前的时间点的能力带来了一些复杂性,这和有关时间旅行和平行宇宙的科幻小说有些相似。例如,在数据库的最初历史中,假设你在周二晚上 5:15 时丢弃了一个关键表,但是一直到周三中午才意识到你的错误。不用苦恼,你取出你的备份,恢复到周二晚上 5:14 的时间点,并上线运行。在数据库宇宙的这个历史中,你从没有丢弃该表。但是假设你后来意识到这并非一个好主意,并且想回到最初历史中周三早上的某个时间。你没法这样做,在你的数据库在线运行期间,它重写了某些 WAL 段文件,而这些文件本来可以将你引向你希望回到的时间。因此,为了避免出现这种状况,你需要将完成时间点恢复后生成的 WAL 记录序列与初始数据库历史中产生的 WAL 记录序列区分开来。
要解决这个问题,PostgreSQL 有一个时间线概念。无论何时当一次归档恢复完成,一个新的时间线被创建来标识恢复之后生成的 WAL 记录序列。时间线 ID 号是 WAL 段文件名的一部分,因此一个新的时间线不会重写由之前的时间线生成的 WAL 数据。实际上可以归档很多不同的时间线。虽然这可能看起来是一个无用的特性,但是它常常扮演救命稻草的角色。考虑到你不太确定需要恢复到哪个时间点的情况,你可能不得不做多次时间点恢复尝试和错误,直到最终找到从旧历史中分支出去的最佳位置。如果没有时间线,该处理将会很快生成一堆不可管理的混乱。而有了时间线,你可以恢复到任何之前的状态,包括早先被你放弃的时间线分支中的状态。
恢复的默认行为是沿着相同的时间线进行恢复,该时间线是基础备份创建时的当前时间线。如果你希望恢复到某个时间线(即你希望回到在一次恢复尝试后产生的某个状态),你需要在 recovery.conf 中指定目标时间线 ID。并且,你不能恢复到早于该基础备份之前分支出去的时间线。
7. 数据复制方式
PostgreSQL 中复制的三种方法
| POSTGRES 的类型 | 谁这样做 | 主要好处 |
|---|---|---|
| 简单的流式复制 | 本地/EC2 | 更易于设置; 高 I/O 性能; 大容量存储 |
| 复制块设备 | RDS/Azure | 适用于数据在云环境中的持久性 |
| 从 WAL 重建 | Heroku/Citus | 后台节点重建; 启用 fork 和 PITR |
- [方法一] 流复制(使用本地存储)
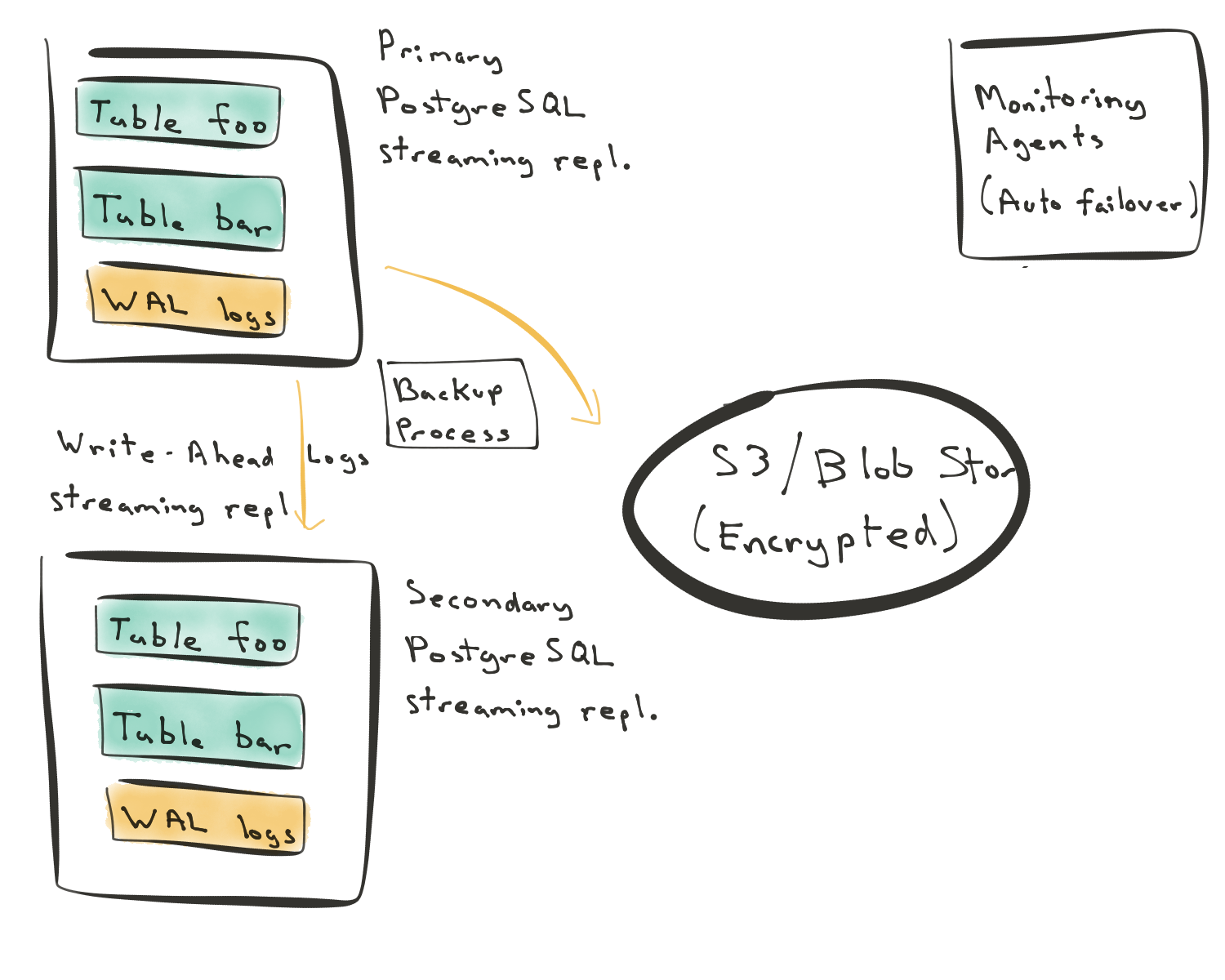
第一种方法,流复制(使用本地存储) 是最常见的方法。你有一个主节点,主节点具有表的数据和预写日志(WAL)。当您修改 Postgres 中的行时,更改首先会被提交到仅附加重做日志,此重做日志称为预写日志或WAL。然后,此 Postgres 的 WAL 日志将流式传输到辅助节点。
在第一种方法中,当您构建新的辅助节点时,新的辅助节点需要从主节点重播整个状态 - 从时间开始。然后,重放操作可能在主节点上引入显着负载。如果数据库的主节点提供实时流量,则此负载变得更加重要。
在此方法中,您可以使用本地磁盘或将持久 volume 附加到实例。在上图中,我们使用的是本地磁盘,因为这是更典型的设置。
- [方法二] 复制块设备
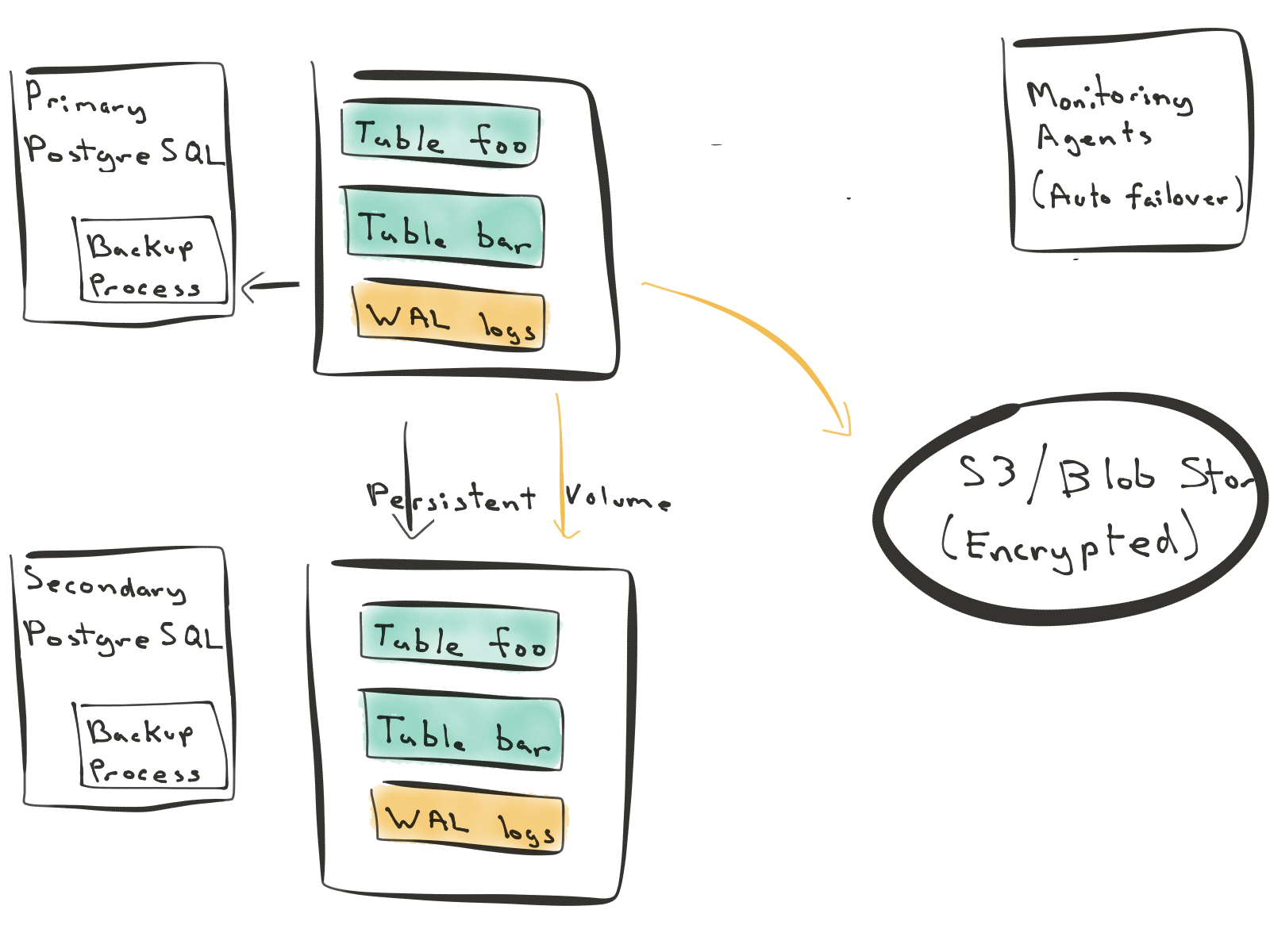
第二种方法依赖于磁盘镜像(有时称为 volume 复制)。在此方法中,更改将写入持久 volume。然后,此 volume 将同步镜像到另一个 volume 中。这种方法的好处是它适用于所有关系数据库。您可以将它用于 MySQL,PostgreSQL 或 SQL Server。
但是,Postgres 中的磁盘镜像复制方法还要求您复制表和 WAL 日志数据。此外,现在每次写入数据库都需要同步通过网络。您不能错过任何一个字节,因为这可能会使您的数据库处于损坏状态。
- [方法三] 从 WAL 重建(并切换到流复制)
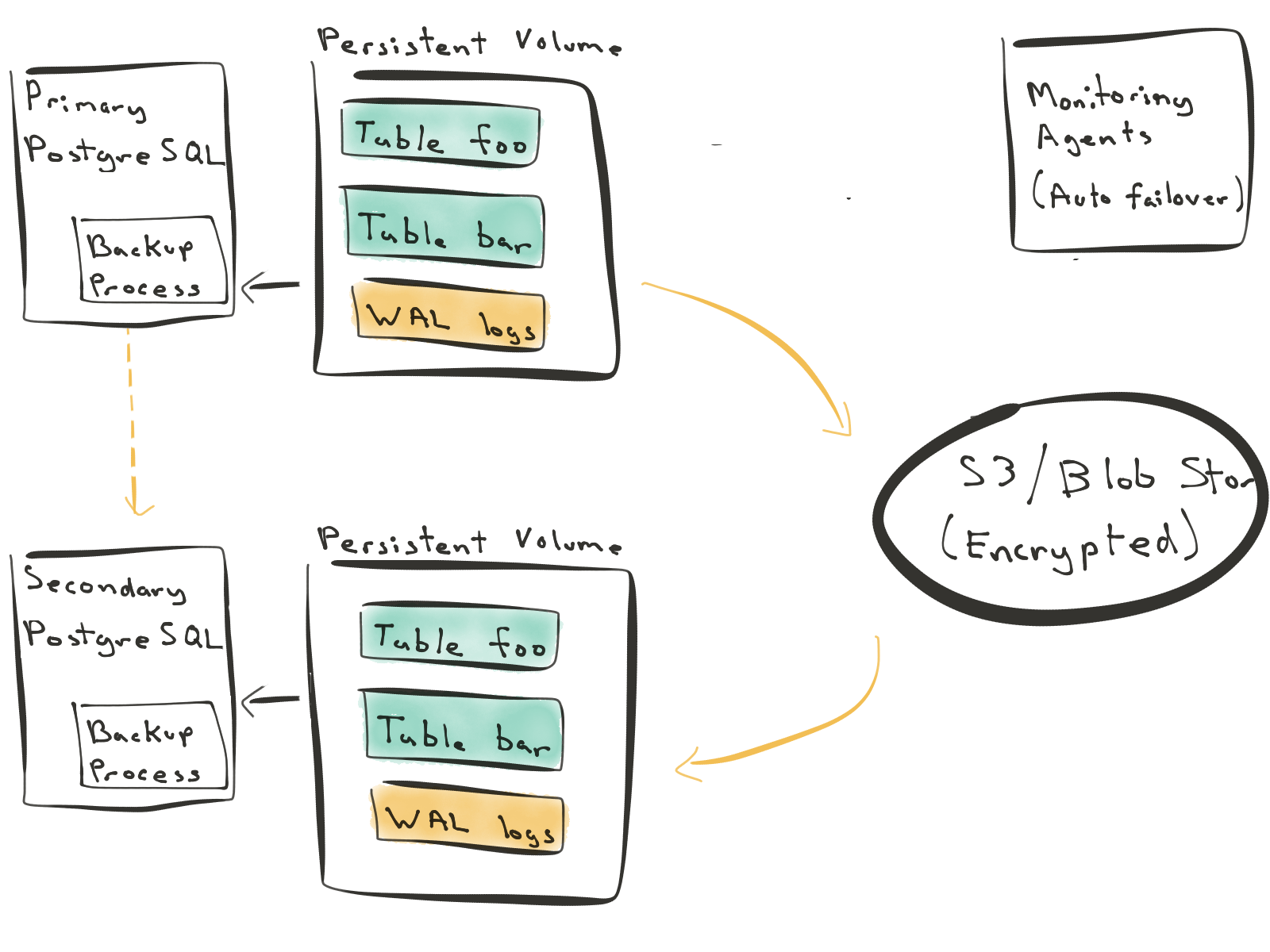
第三种方法,将复制和灾难恢复过程彻底改变。您写入主节点,主节点每天执行完整数据库备份,每 60 秒执行一次增量备份。
当您需要构建新的辅助节点时,辅助节点会从备份重建其整个状态。这样,您不会在主数据库上引入任何负载。您可以启动新的辅助节点并从 S3 / Blob 存储重建它们。当辅助节点足够接近主节点时,您可以从主节点开始流式传输 WAL 日志并赶上它。在正常状态下,辅助节点跟随主节点。
在这种方法中,预写日志优先。这种设计适用于更加云原生的架构。您可以随意调出或击落副本,而不会影响关系数据库的性能。您还可以根据需要使用同步或异步复制。
8. 参考链接地址
赠人玫瑰,手有余香