纸上得来终觉浅,绝知此事要躬行。

1. 问题起因
简述问题的起因和表象,用于分析原因。
- 我们常常使用
supervisor来管理服务进程,因为其能够提供很好且很健全的便捷支持,比如服务异常退出之后可以自行重启等。同样,在部署服务的时候也是可以使用该工具进行管理。为了不中断服务对产品进行更新,我们通常会使用信号量来不中断的重启服务。当然,我们的supervisor是支持接收HUP信号量的。
# 使用方式
$ sudo supervisorctl signal HUP app-test:*
- 但是,我们在使用的过程中发现,在使用
HUP的时候,会发生进程并没有重启的异常情况。如下所示,我们使用supervisor管理了一个产品的服务,一个是web服务,另一个是对应的worker服务,其中worker服务启动的是一个celery服务。
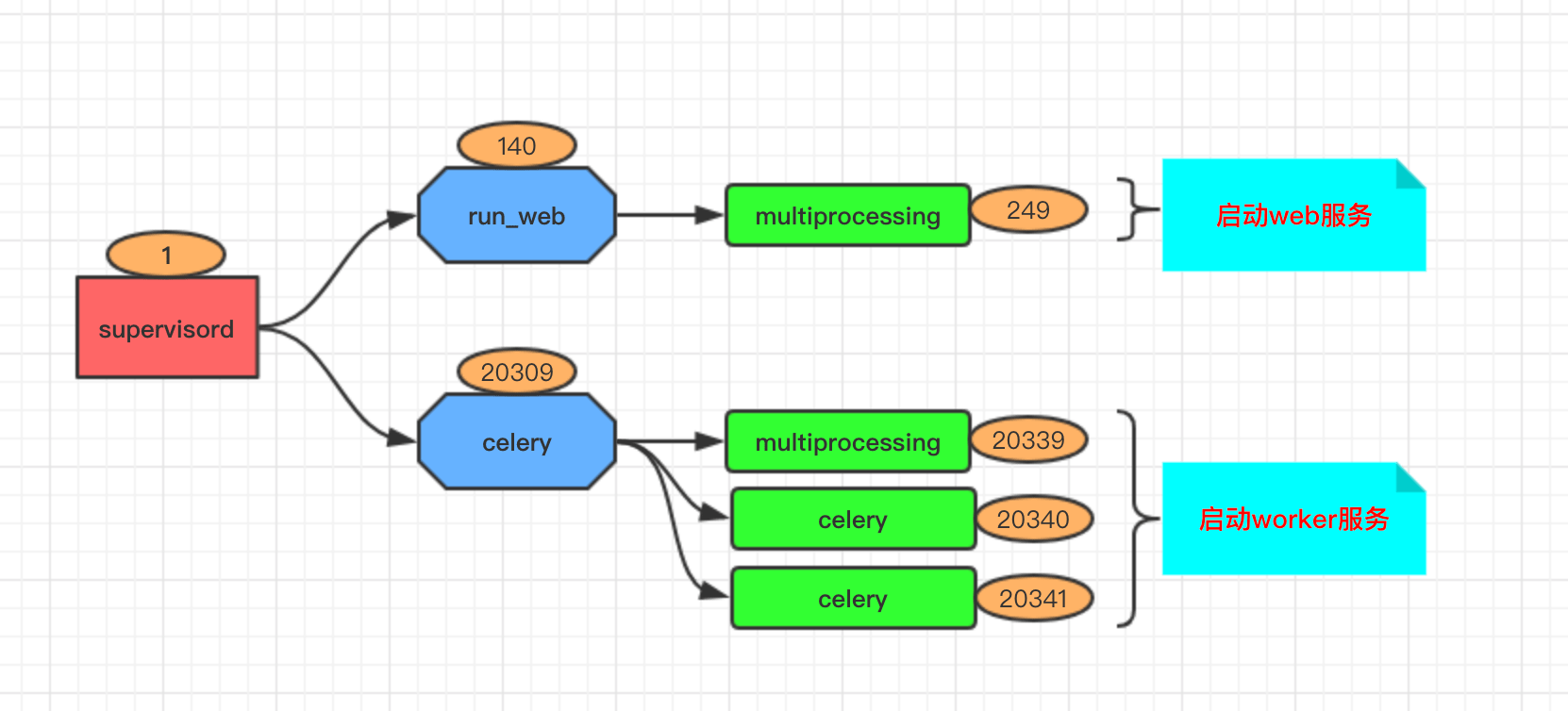
root 1 0 00:00:17 /usr/bin/python /usr/bin/supervisord -n -c /etc/supervisor/supervisord.conf
root 140 1 00:00:56 python3 -m run_web
root 249 140 00:00:00 /usr/bin/python3 -c from multiprocessing.semaphore_tracker import main;main(3)
root 20309 1 00:00:01 /usr/bin/python3 /usr/local/bin/celery -A remarkable.worker.app worker -n norm-%n@%h -l debug -c 2 -Q celery
root 20339 20309 00:00:00 /usr/bin/python3 -c from multiprocessing.semaphore_tracker import main;main(3)
root 20340 20309 00:00:00 /usr/bin/python3 /usr/local/bin/celery -A remarkable.worker.app worker -n norm-%n@%h -l debug -c 2 -Q celery
root 20341 20309 00:00:00 /usr/bin/python3 /usr/local/bin/celery -A remarkable.worker.app worker -n norm-%n@%h -l debug -c 2 -Q celery
- 但是使用
HUP信号量来重启服务之后,查看对应的进程关系发现,有一个20339的子进程并没有退出,而且提示信息变成了<defunct>。这就导致我很频繁重启服务的时候,会产生很多没有用的进程占用内存等资源。
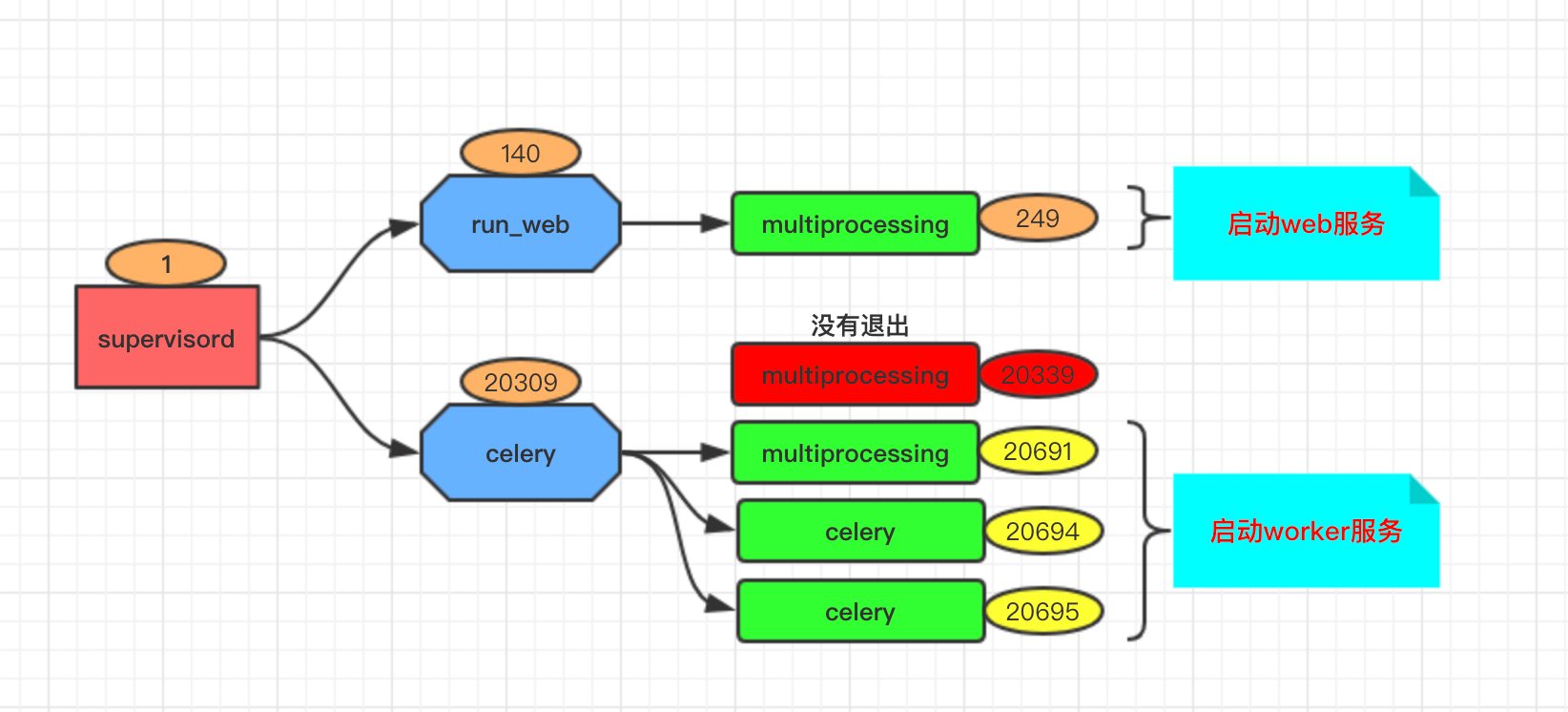
root 1 0 00:00:17 /usr/bin/python /usr/bin/supervisord -n -c /etc/supervisor/supervisord.conf
root 140 1 00:00:56 python3 -m run_web
root 249 140 00:00:00 /usr/bin/python3 -c from multiprocessing.semaphore_tracker import main;main(3)
root 20309 1 00:00:04 /usr/bin/python3 /usr/local/bin/celery -A remarkable.worker.app worker -n norm-%n@%h -l debug -c 2 -Q celery
root 20339 20309 00:00:00 [python3] <defunct>
root 20691 20309 00:00:00 /usr/bin/python3 -c from multiprocessing.semaphore_tracker import main;main(3)
root 20694 20309 00:00:00 /usr/bin/python3 /usr/local/bin/celery -A remarkable.worker.app worker -n norm-%n@%h -l debug -c 2 -Q celery
root 20695 20309 00:00:00 /usr/bin/python3 /usr/local/bin/celery -A remarkable.worker.app worker -n norm-%n@%h -l debug -c 2 -Q celery
2. 排除经过
简单排除,发现 Celery 并不完美支持 Hup 信号量!
- 那么,我们看下是什么原因导致上述问题的出现呢?通过阅读
celery的官方文档 得知,其实它是支持HUP信号量,虽然是处理试用阶段并不推荐用于正式环境。
Other than stopping, then starting the worker to restart, you can also restart
the worker using the HUP signal. Note that the worker will be responsible for
restarting itself so this is prone to problems and isn’t recommended in production:
$ kill -HUP $pid
Note
Restarting by HUP only works if the worker is running in the background as a
daemon (it doesn’t have a controlling terminal).
HUP is disabled on macOS because of a limitation on that platform.
- 我们可以看到,启动时候调用的是
Python系统自带的多进程库multiprocessing中的semaphore_tracker函数,但是在其定义的源代码中并没有发现处理和接受HUP信号量的响应代码程序。
def main(fd):
'''Run semaphore tracker.'''
# protect the process from ^C and "killall python" etc
signal.signal(signal.SIGINT, signal.SIG_IGN)
signal.signal(signal.SIGTERM, signal.SIG_IGN)
if _HAVE_SIGMASK:
signal.pthread_sigmask(signal.SIG_UNBLOCK, _IGNORED_SIGNALS)
......
3. 结果总结
后续发现,为什么在 docker 容器中,才会出现该问题!
- 咳咳咳,很多天后,无意间我在
StackOverflow中看到有个人提了一个问题: 在 docker 中使用 python 多进程库 multiprocessing 系统就奔溃了。
# mp.py
import multiprocessing as mp
def do_something():
print('something')
if __name__ == '__main__':
ctx = mp.get_context("spawn")
p = ctx.Process(target=do_something, args=tuple())
p.start()
p.join()
version: '3.6'
services:
bug:
build:
context: .
environment:
- PYTHONUNBUFFERED=1
command: su -c "python3.6 forever.py"
from time import sleep
if __name__ == '__main__':
i = 0
while True:
sleep(1.0)
i += 1
print(f'hello {i:3}')
# To reproduce bug run in first terminal:
docker-compose build && docker-compose up
# In the second one
docker exec -it downloadmovies_bug_1 python3 mp.py
通过阅读
georgexsh同学的回答得知,如果我们在使用multiprocessing模块的时候使用了spawn模式,Python默认会启动一个信号跟踪器进程(semaphore_tracker)来防止信号量泄露。这个进程是由mp.py启动得来的,但是在mp.py退出之后才退出,所以不会被mp.py捕获到,而是由系统的init进程接管。问题在于容器中PID为1的进程并不是传统意义上的init进程,而是我们通过entrypoint或cmd传入的命令,所以这里PID为1的进程是su -c命令。因此信号跟踪器进程(semaphore_tracker)传递给了su命令,但是它却并不识别。su认为子进程是命令进程(forever.py)错误,没有检查关系直接退出了。当PID为1进程退出时,内核杀死容器中的所有其他进程,包括forever.py。我自己测试的时候,发现通过另一个终端执行
python3 mp.py(27) 命令会启动两个进程。当命令执行完成之后,semaphore_tracker(28) 会交给python3(27) 来处理进行终止。
# 容器内部执行 ps -ef 命令
UID PID PPID C STIME TTY TIME CMD
root 1 0 0 07:28 ? 00:00:00 su -c python3.6 forever.py
root 7 1 0 07:28 ? 00:00:00 python3.6 forever.py
root 8 0 0 07:28 pts/0 00:00:00 bash
root 27 8 2 07:30 pts/0 00:00:00 python3 mp.py
root 28 27 1 07:30 pts/0 00:00:00 /usr/local/bin/python3 -c from multiprocessing.semaphore_tracker import main;main(3)
root 29 27 2 07:30 pts/0 00:00:00 [python3] <defunct>
root 20 0 0 07:29 pts/1 00:00:00 bash
root 30 20 0 07:30 pts/1 00:00:00 ps -ef
4. 解决方法
总结出现该问题的原因,以及解决方法!
- 还有一种比较常用的方式,就是使用
inv来启动其他服务,包括celery等。这样就又会出现同样的问题,就是inv工具本身也并支持Hup信号量,导致服务被杀死了,但是本身启动的子进程并没有得到有效的管理,成为了为人看管的孤儿进程,游离在容器的进程之中。
# celery
supervisor
|__ celery(父) --> 被杀死但是子没死
|__ celery(子)
# invoke
supervisor
|__ invoke --> 被杀死导致启动的bash没死
|__ bash(父)
|__ celery(子)
正常来说,通过
bash命令启动的子服务,都会在主服务被杀死的时候,一并进行清除的,并不会存在孤儿进程的情况。但是,因为工具本身并不支持信号量的形式,导致产生的子进程无处安放,就会出现各种各样的问题。解决方法就是,通过
bash命令将启动celery命令进行保证一下,并且在启动服务的时候使用exec命令,将子进程提升一个等级,这样就不会因为父进程死亡导致成为孤儿进程的情况。虽然还是不够优雅,但是可以解决问题。
WORK_DIR=$(dirname $(realpath -s "$BASH_SOURCE"))
args=("$@")
for ((i=0; i<${#args[@]}; i++)); do
if [ "${args[$i]}" == "-B" ] || [ "${args[$i]}" == "beat" ]; then
rm -f /tmp/celerybeat*
fi
done
exec celery "$@"
5. 参考文档
送人玫瑰,手有余香!