纸上得来终觉浅,绝知此事要躬行。
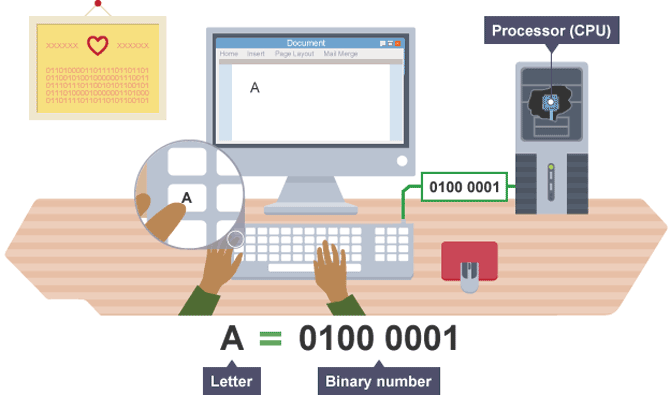
1. 基础知识
关于
str、bytes和unicode,不管对于新手还是老手来说,都是一个很难理解的问题。很多人都在抱怨在Python下,自己的写的代码总是出现乱码,究其原因,还是因为并没有深刻理解其核心的用法和设计思路。而在Python3中,再也不用担心这个问题了,因为作者已经解决了这个问题,我们只管使用就好了。
1.1 字符集
字符 - Character
- 字符是一个信息单位,字母、数字、标点符号、中文汉字都是字符。另外还有控制字符,如打印机或其它显示设备的命令,比如
Tab、回车、退格等等。单个或者多个字符合起来就是一个字符串。
字符集 - Charset
- 字符集是多个字符的集合,是一个系统支持的所有抽象字符的集合。包括各国家文字、标点符号、图形符号、数字等。
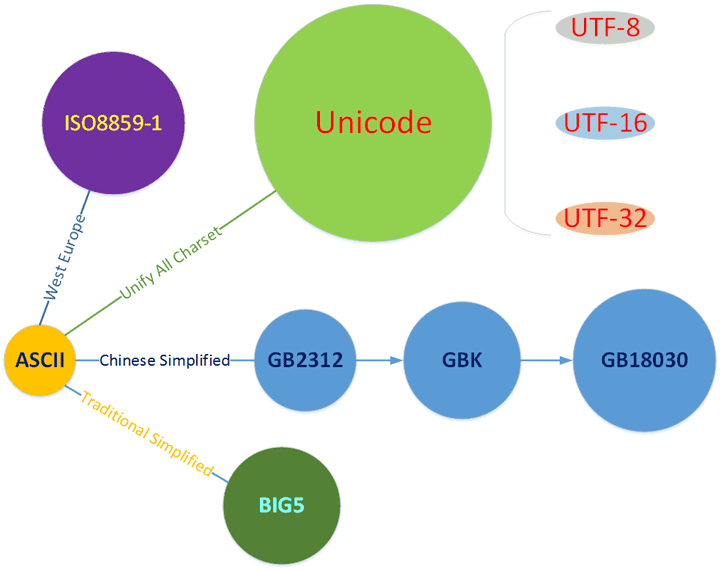
常见的字符集种类
GB2312
GB2312是中华人民共和国国家标准简体中文字符集,通常简称GB。这个标准共收录6763个汉字,基本满足了汉字的计算机处理需要,它所收录的汉字已经覆盖中国大陆99.75%的使用频率。但对于人名、古汉语等方面出现的罕用字和繁体字,GB2312不能处理,因此后来引入了GBK和GB18030来解决这个问题。
GBK
GBK全称汉字内码扩展规范。它兼容GB2312,也支持GB2312编码不支持的部分中文姓,中文繁体,日文假名,还包括希腊字母以及俄语字母等字母。不过这种编码不支持韩国字,也是其在实际使用中与unicode编码相比欠缺的部分。
GB18030
GB18030是最新的变长度多字节字符集,对GB2312完全向后兼容,与GBK基本向后兼容;共收录汉字70,244个。我记得Windows中文默认就使用了GB18030字符集。
ASCII
ascii是美国信息交换标准代码的简称。是基于拉丁字母的一套计算机编码系统。它主要用于显示现代英语。ASCII的局限在于只能显示26个基本拉丁字母、阿拉伯数目字和英式标点符号。ascii能够成为标准是因为在计算机历史的早期,以美国为代表的英语系国家主导了计算机的行业,所以肯定优先方便英语使用。
Unicode
Unicode是计算机科学领域里的一项业界标准。它对世界上大部分的文字系统进行了整理、编码,使得计算机可以用更为简单的方式来呈现和处理文字。
UTF-8
UTF-8的8-bit Unicode Transformation Format的英文缩写,可以看出**Unicode是「字符集」,而UTF-8是其对应可变长度的「编码规则」。**UTF-8是一种针对Unicode的可变长度字符编码,它可以使用1~4个字节表示一个符号,根据不同的符号而变化字节长度。同时,还有UTF-16、UTF-32等,不过是用的不多。
1.2 字符编码
字符编码 - Character Encoding
- 把字符集中的字符编码为指定集合中某一对象,以便在计算机中存储和通过通信网络的传递。把存储介质中获取的二进制比特流或者网络接收到数据,通过字符集翻译成字符就是解码。更程序化地说,字节和字符串之间的来回转换由两个术语定义。
- 编码是根据一个想要的编码名称,把一个字符串翻译为其原始字节形式。解码是根据其编码名称,把一个原始字节串翻译为字符串形式的过程。
示例说明
- 这里是在
Python2的常见的错误信息,提示语法错误,因为在文件中包含了不是ASCII的字符,不能编码,可以参考pep-0263文档。
msg = '这是一个测试'
print(msg)
$ python print_msg.py
File "print_msg.py", line 1
SyntaxError: Non-ASCII character '\xe8' in file print_msg.py on line 1, but no encoding declared; see http://python.org/dev/peps/pep-0263/ for details
- 而让程序不报错,有以下两种通用的修改方式。第一种就是在文件开头显示的指定编码字符集,第二种是重新设置系统的默认文件编码方式。不推荐使用第二种,因为这是有隐患的。
# coding=utf-8
import sys
reload(sys)
sys.setdefaultencoding('utf8')
2. 区别联系
2.1 核心要点
str和unicode是两种字符串数据类型,他们都是basestring的子类。unicode对象,存储的是一个抽象的code points序列。str对象,存储字节序列,计算机能看懂,人类不好理解。但它可以被映射到一个代码点序列。不同的unicode编码方法(如UTF-8、UTF-7等)映射不同的字节序列到代码点。
- 在
Python2中,普通的字符类型就是str,它是字符的序列。而对应的字符就是Python3中的Bytes,也就是字节。在Python2中,Python3的Bytes就是Python2的str,而在Python3中,Python3的str就是Python2的unicode。
# 在Python2中,我们发现str和Bytes是一样的
In [1]: s = 'abc' # str
...: u = u'abc' # Unicode
...: b = b'abc' # Bytes
...:
In [2]: s, u, b
Out[2]: ('abc', u'abc', 'abc')
# 在Python2中,我们发现str和Unicode是一样的
In [1]: s = 'abc' # str
...: u = u'abc' # Unicode
...: b = b'abc' # Bytes
...:
In [2]: s, u, b
Out[2]: ('abc', 'abc', b'abc')
2.2 str 和 unicode 的转换
在
Python2中str直接使用Bytes进行存储。
- 创建
str对象,就直接使用''就可以了,而在Python2中对应的str类型其实Bytes,而一个中文占三个字节,所以我们会看到其对应的长度为6了。
# 在Python2中,创建一个str对象
In [1]: s = '中文'
In [2]: s
'\xe4\xb8\xad\xe6\x96\x87'
In [3]: len(s)
6
In [4]: s = 'abc'
In [5]: s
'abc'
In [6]: len(s)
3
- 创建
unicode有两种方法,第一种就是在其前添加u就可以了,第二种就是使用unicode方法,但是需要指定编码格式,不然就报错的。
# 在Python2中,创建一个unicode对象
In [1]: u'中文'
u'\u4e2d\u6587'
In [2]: unicode('abc')
u'abc'
In [3]: unicode('中文')
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
UnicodeDecodeError: 'ascii' codec can't decode byte 0xe4 in position 0: ordinal not in range(128)
In [4]: unicode('中文', 'utf-8')
u'\u4e2d\u6587'
In [5]: len(unicode('中文', 'utf-8'))
2
In [6]: unicode('中文', 'gb18030')
u'\u6d93\ue15f\u6783'
In [7]: len(unicode('中文', 'gb18030'))
3
- 我们注意到,在
Python2中str(Bytes)转换成unicode需要时用decode解码操作,而使用encode编码会报错。 - 而将
unicode转换成str(Bytes)就需要时用encode解码操作,而使用decode编码会报错。
# str -> unicode
In [1]: s = '中文'
In [2]: s
'\xe4\xb8\xad\xe6\x96\x87'
In [3]: s.decode('utf-8')
u'\u4e2d\u6587'
In [4]: print(s)
中文
str -> decode() -> unicodeunicode -> encode() -> str
# unicode -> str
In [5]: u = s.decode('utf-8')
In [6]: u.encode('utf-8')
'\xe4\xb8\xad\xe6\x96\x87'
In [7]: print(u.encode('utf-8'))
中文
In [8]: print(u.encode('gbk'))
????
2.3 str 和 bytes 的转换
在
Python3中str直接使用unicode进行存储。
- 在
Python3中str直接使用unicode进行存储,使输出的可读性变好了,但事实上依然可以使用Bytes存储字节序列。 - 将
str转化为Bytes,也是有两种方式。第一种是直接使用b前缀就好了,但不能转换非ASCII的字符。第二种是使用bytes函数,但需要指定编码规则,否则会报错的。
In [1]: s = '中文'
In [2]: s
Out[2]: '中文'
In [3]: len(s)
Out[3]: 2
In [4]: bytes('中文', 'utf-8')
Out[4]: b'\xe4\xb8\xad\xe6\x96\x87'
In [5]: len(bytes('中文', 'utf-8'))
Out[5]: 6
In [6]: b'abc'
Out[6]: b'abc'
In [7]: b'中文'
File "<ipython-input-7-241a368e5c3e>", line 1
b'中文'
^
SyntaxError: bytes can only contain ASCII literal characters.
str -> encode() -> bytesbytes -> decode() -> str
In [8]: s = '中文'
In [9]: s
Out[9]: '中文'
In [10]: s.encode('utf-8')
Out[10]: b'\xe4\xb8\xad\xe6\x96\x87'
In [13]: b = s.encode('utf-8')
In [14]: b
Out[14]: b'\xe4\xb8\xad\xe6\x96\x87'
In [15]: b.decode('utf-8')
Out[15]: '中文'
In [16]: b.decode('gbk')
---------------------------------------------------------------------------
UnicodeDecodeError Traceback (most recent call last)
<ipython-input-16-1420621f1688> in <module>()
----> 1 b.decode('gbk')
UnicodeDecodeError: 'gbk' codec can't decode byte 0xad in position 2: illegal multibyte sequence
- 在
Python3中依然可以使用str这个类,但不推荐使用。因为如果给一个bytes类型对象使用str方法,会将b''都包含在内了,这样是很尴尬的。
In [17]: b
Out[17]: b'\xe4\xb8\xad\xe6\x96\x87'
In [18]: str(b)
Out[18]: "b'\\xe4\\xb8\\xad\\xe6\\x96\\x87'"



