Python 语言旨在使复杂任务变得简单,所以更新迭代的速度比较快,需要我们紧跟其步伐!
新版本的发布,总是会伴随着新特性和新功能的产生,我们在升级版本之前首先就是需要了解和属性这些要点,才可能会在之后的编程中灵活的使用到。迫不及待,蓄势待发,那现在就让我们开始吧!

1. PEP 584
新的语法特性:简化字典的更新操作
在新版的
Python中,字典类新增了两个语法特性,分别是合并 (|) 与更新 (|=) 运算符,用于替代现有的dict.update和{**d1, **d2}字典的合并方法。当然,你也可以选择不适用,非强制。如果我们想把字典
d中cheese对应的值更新为字典e中cheese对应的值,在之前的方法中,我们可以使用d.update(e)来更新。除了通过update来更新之外,也可以通过{**d, **e}来更新。d.update(e)=> 会修改字典d本身的值{**d, **e}=> 不会修改字段d/e的值,会生成一个新的字典
>>> d = {'spam': 1, 'eggs': 2, 'cheese': 3}
>>> e = {'cheese': 'cheddar', 'aardvark': 'Ethel'}
# 按位或运算符实现合并
>>> d | e
{'spam': 1, 'eggs': 2, 'cheese': 'cheddar', 'aardvark': 'Ethel'}
>>> e | d
{'cheese': 3, 'aardvark': 'Ethel', 'spam': 1, 'eggs': 2}
# 合并后直接替换
>>> d |= e
>>> d
{'spam': 1, 'eggs': 2, 'cheese': 'cheddar', 'aardvark': 'Ethel'}
>>> e |= d
>>> e
{'cheese': 3, 'aardvark': 'Ethel', 'spam': 1, 'eggs': 2}
- 下面是,官方
PEP中给出的参考实现示例,以及使用新语法特性的便捷和好处。
def __or__(self, other):
if not isinstance(other, dict):
return NotImplemented
new = dict(self)
new.update(other)
return new
def __ror__(self, other):
if not isinstance(other, dict):
return NotImplemented
new = dict(other)
new.update(self)
return new
def __ior__(self, other):
dict.update(self, other)
return self
# matplotlib/backends/backend_svg.py
# 没使用新语法
attrib = attrib.copy()
attrib.update(extra)
attrib = attrib.items()
# 使用新语法特性的好处
attrib = (attrib | extra).items()
2. PEP 585
新的语法特性:内置数据类型的类型提示
- 这个
PEP提议,支持类型模块中当前可用的所有标准集合中的泛型语法,即Python 3.9启用了typing模块提供的所有标准集合中对泛型语法的支持。
>>> list[str]
list[str]
>>> type(list[str])
types.GenericAlias
>>> tuple[int, ...]
tuple[int, ...]
>>> type(tuple[int, ...])
types.GenericAlias
>>> ChainMap[str, list[str]]
collections.ChainMap[str, list[str]]
>>> type(ChainMap[str, list[str]])
types.GenericAlias
>>> l = list[str]()
[]
>>> list is list[str]
False
>>> list == list[str]
False
>>> list[str] == list[str]
True
>>> list[str] == list[int]
False
- 这里需要注意的是,这里的类型提示并不是强制的,即使给的值不是正确的,也不会报错。如果需要强制检测的话,我们可以使用
mypy工具。
>>> isinstance([1, 2, 3], list[str])
TypeError: isinstance() arg 2 cannot be a parameterized generic
>>> issubclass(list, list[str])
TypeError: issubclass() arg 2 cannot be a parameterized generic
>>> isinstance(list[str], types.GenericAlias)
True
- 在类型标注中,现在我们可以使用内置多项集类型,例如
list和dict作为通用类型,而不必从typing模块中导入对应的大写形式类型名(例如List和Dict)。标准库中的其他一些类型现在同样也是通用的,例如queue.Queue。
# 设置字典中使用类型提示
person: dict = {'name': 'Tom', 'age': 1}
# 可以在函数定义时限定传入类型(列表)
def greet_all(names: list[str]) -> None:
for name in names:
print("Hello", name)
# 可以在函数定义时限定传入类型(字典)
def find(haystack: dict[str, list[int]]) -> int:
...
3. PEP 614
新的语法特性:放宽对装饰器的语法限制
以往装饰器(
decorator)必须是命名的调用对象,通常是用函数或类定义的。因为使用不多的原因,大多数人并不认为旧的装饰器语法具有限制性。而在PEP 614中允许装饰器成为任何可调用的表达式。在
PyQT中使用signals和slots来连接各个组件(回调方式),我们可以执行如下代码,将按钮的单击信号连接到插槽say_hello()这个函数。当用户点击之后,就会触发函数执行对应语句。
button = QPushButton("Say hello")
@button.clicked.connect
def say_hello():
message.setText("Hello, World!")
- 假设现在我定义了多个按钮,为了方便管理和控制,把它们存储在一个字典中。但是,这样怎么使用装饰器将按钮和对应函数相关联呢?因为在早期的版本中,使用装饰符时不能使用方括号访问对应项的,所以需要将代码改造成如下方式来完成任务。
# 设置多按钮字典
buttons = {
"hello": QPushButton("Say hello"),
"leave": QPushButton("Goodbye"),
"calculate": QPushButton("3 + 9 = 12"),
}
# 绑定按钮和对应函数
hello_button = buttons["hello"]
@hello_button.clicked.connect
def say_hello():
message.setText("Hello, World!")
- 在
Python 3.9中,这些限制被取消了,可以使用任何表达式,包括一个访问字典中的条目。这样,上面的任务就变得简单多了。
# 在装饰器中使用方括号访问对应项
@buttons["hello"].clicked.connect
def say_hello():
message.setText("Hello, World!")
- 虽然这不是一个很大的改变,但是它允许我们在少数情况下编写更简洁的代码。扩展语法,还使得在运行时动态选择装饰器变得更加容易。下面这个示例中,
normal装饰器不会改变函数的直接输出对应内容,而@whisper和@shout装饰器会使函数返回的任何文本变成大写或小写。可以在字典中存储对这些decorator的引用,然后获取用户输入执行对应函数。
import functools
def normal(func):
return func
def shout(func):
@functools.wraps(func)
def shout_decorator(*args, **kwargs):
return func(*args, **kwargs).upper()
return shout_decorator
def whisper(func):
@functools.wraps(func)
def whisper_decorator(*args, **kwargs):
return func(*args, **kwargs).lower()
return whisper_decorator
DECORATORS = {"normal": normal, "shout": shout, "whisper": whisper}
voice = input(f"Choose your voice ({', '.join(DECORATORS)}): ")
@DECORATORS[voice]
def get_story():
...
print(get_story())
4. PEP 616
新的内置特性:新增移除前缀和后缀的字符串方法
- 在新版中,增加了
str.removeprefix(prefix)和str.removesuffix(suffix)用于方便地从字符串移除不需要的前缀或后缀。也增加了bytes,bytearray以及collections.UserString的对应方法。str.removeprefix(prefix)=> 删除字符串前缀str.removesuffix(suffix)=> 删除字符串后缀
- 当然,同时也增加了
bytes、bytearray以及collections.UserString的对应方法。
# find_recursionlimit.py
# 没使用新特性
if test_func_name.startswith("test_"):
print(test_func_name[5:])
else:
print(test_func_name)
# 使用新特性的好处
print(test_func_name.removeprefix("test_"))
# cookiejar.py
# 没使用新特性
def strip_quotes(text):
if text.startswith('"'):
text = text[1:]
if text.endswith('"'):
text = text[:-1]
return text
# 使用新特性的好处
def strip_quotes(text):
return text.removeprefix('"').removesuffix('"')
- 下面是,官方
PEP中给出的参考实现示例。
def removeprefix(self: str, prefix: str, /) -> str:
if self.startswith(prefix):
return self[len(prefix):]
else:
return self[:]
def removesuffix(self: str, suffix: str, /) -> str:
# suffix='' should not call self[:-0].
if suffix and self.endswith(suffix):
return self[:-len(suffix)]
else:
return self[:]
5. PEP 615
新的库模块:IANA 时区数据库现在已包含于标准库的 zoneinfo 模块
- 新版本中,新增的
zoneinfo模块为标准库引入了 IANA 时区数据库,其添加的zoneinfo.ZoneInfo类是一个基于系统时区数据的实体datetime.tzinfo实现。我们在之前编写代码的时候,如果需要获取某个地方的时区,需要借助于第三方库pytz来完成。而在Python 3.9中内置了时区获取的库zoneinfo。
>>> from zoneinfo import ZoneInfo
>>> from datetime import datetime, timedelta
>>> # 夏令时
>>> dt = datetime(2020, 10, 31, 12, tzinfo=ZoneInfo("America/Los_Angeles"))
>>> print(dt)
2020-10-31 12:00:00-07:00
>>> dt.tzname()
'PDT'
>>> # 标准时间
>>> dt += timedelta(days=7)
>>> print(dt)
2020-11-07 12:00:00-08:00
>>> print(dt.tzname())
PST
6. graphlib
新的库模块:图的拓扑排序实现现在已由新的 graphlib 模块提供
- 添加了新的
graphlib模块,其中包含graphlib.TopologicalSorter类来提供图的拓扑排序功能。
>>> graph = {"D": {"B", "C"}, "C": {"A"}, "B": {"A"}}
>>> ts = TopologicalSorter(graph)
>>> tuple(ts.static_order())
('A', 'C', 'B', 'D')
7. Note
主要记录语法等的变更新和说明
- [1] 标准库中的新特性
优化 str.replace 方法输出方式。
在 math 库中新增最大公约数与最小公倍数方法。
添加了 os.pidfd_open() 以允许不带竞争和信号的进程管理。
# 之前版本:"".replace("",s,n)返回空字符串
>>> "".replace("", "log") │
'log'
>>> "".replace("", "log", 1) │
''
# 现在版本: "".replace("",s,n)将返回s的值
>>> "".replace("", "log")
'log'
>>> "".replace("", "log", 1)
'log'
- [2] 解释器的改进
从 C 扩展类型的方法快速访问模块状态
许多 Python 内置类型,如 range, tuple, set, list, dict 通过使用 vectorcall 使效率提升。
垃圾回收不会因恢复的对象而阻塞,即进行某些复活对象的收集时,不会阻止对所有仍然无法访问对象的收集。CPython 使用基于 PEG 的新解析器来替代 LL,新解析器的性能与旧解析器大致相当但其语法特性更加灵活。
# 使用旧的解释器LL
$ python3.9 -X oldparser test.py
$ PYTHONOLDPARSER=1 python3.9 test.py
- [3] 性能改进
优化了多线程应用中的信号处理。
浮点数运算中的 floor division 现在会有更好的性能。__import__() 现在会引发 ImportError 而不是 ValueError。
当另一集合远大于基础集合的情况下优化了 difference_update() 的性能。
使用 UTF-8 和 ascii 编解码器解码短 ASCII 字符串现在会加快大约 15%。
优化了在推导式中为临时变量赋值的惯用方式,即推导式 for y in [expr] 会与赋值语句 y = expr 一样快。
# 不同于 := 运算符,这个惯用方式不会使变量泄露到外部作用域中
sums = [s for s in [0] for x in data for s in [s + x]]
- [4] 更新纪要
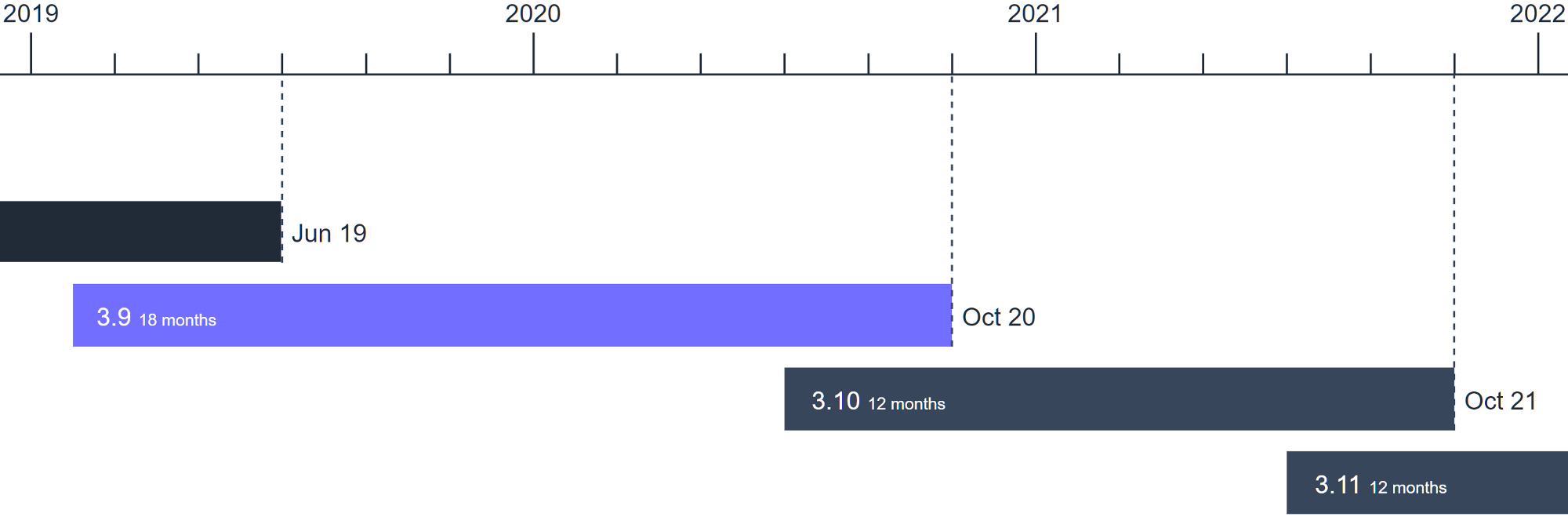
在 PEP 602 中,CPython 发布进程采用年度发布周期(每年都会看到 Python 的新版本)。
8. Links
送人玫瑰,手有余香!
- Python 3.9 有什么新变化
- Python 3.9: Cool New Features for You to Try
- PEP 602 – Annual Release Cycle for Python
- PEP 584 – Add Union Operators To dict
- PEP 585 – Type Hinting Generics In Standard Collections
- PEP 614 – Relaxing Grammar Restrictions On Decorators
- PEP 616 – String methods to remove prefixes and suffixes
- PEP 593 – Flexible function and variable annotations
- PEP 573 – Module State Access from C Extension Methods
- PEP 617 – New PEG parser for CPython
- PEP 615 – Support for the IANA Time Zone Database in the Standard Library



