本文主要是阅读《MySQL 技术内幕》/《MariaDB 简单入门》总结而来,有需求的话可以阅读原著。

1. 数据类型
数据类型是数据的一种属性,它可以决定数据的存储格式、有效范围和相应的限制。
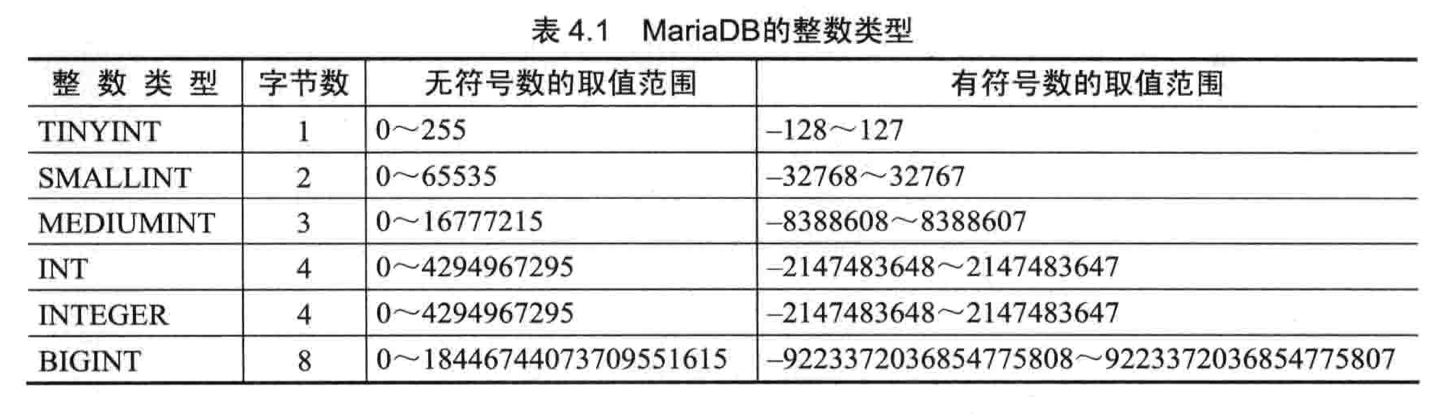
- 整数类型
| 数据类型 | 包含的种类 |
|---|---|
| 整数类型 | MySQL: integer/smallint;扩展: tinyint/mediumint/bigint |
- 浮点数类型和定点数类型
| 数据类型 | 包含的种类 | 注意要点 |
|---|---|---|
| 浮点数类型 | 单精度(float)/双精度(double) |
M为精度(数据总长度);D为标度(小数点精度) |
| 定点数类型 | decimal(M,D)或dec(M,D) |
decimal和double的取值范围相同,但decimal由M和D决定 |

- 日期与时间类型
| 数据类型 | 包含的种类 |
|---|---|
| 日期与时间类型 | year/date/time/datetime/timestamp |
year |
插入数值的格式YYYY;超过取值范围的年份,会插入 0000,查询显示为空 |
date |
插入数值的格式YYYY-MM-DD;分隔符可以为任意特殊字符;current_date和now()表示当前日期 |
time |
插入数值的格式D HH:MM:SS,如2 20:20表示68:20:00;current_time和now()表示当前时间 |
datetime |
插入数值的格式YYYY-MM-DD HH:MM:SS;分隔符可以为任意特殊字符;now()表示当前日期和时间 |
timestamp |
大致与datetime使用方法类似,但是取值范围比较小;timestamp可以根据时区来显示日期和时间 |

- 字符串类型
| 数据类型 | 对于解释 |
|---|---|
char |
定长字符串,取值范围0~255 |
varchar |
变长字符串,取值范围0~65535 |
text |
包含类型tinytext/text/mediumtext/longtext |
enum |
枚举类型的定义格式为enum('value1', 'value2', ...);最多取值范围为65535个值 |
set |
基本形式和enum类型一样,但值可以为列表中的一个或多个元素组成;最多只能有64个元素组成 |

- 二进制类型
| 数据类型 | 对于解释 |
|---|---|
| 二进制类型 | binary/varbinary/bit/tinyblog/blob/meduimblob/longblob |
blob |
blob类型主要用来存储图片、PDF 文档等二进制文件 |
binary |
binary/varbinary/bit类型都是在创建时指定最大长度 |

常见问题以及解答
【问题 1】MariaDB 中什么数据类型能够存储路径?
MariaDB中可以使用char、varchar和text来存储路径。但是,如果路径中使用\符号时会被自动过滤掉。可以使用/或\\\\来代替,这样MariaDB就不会自动过滤路径的分隔符号了。
【问题 2】MariaDB 中如何使用布尔类型?
- 在
SQL标准中,存储bool和boolean类型。MariaDB为了支持SQL类型,也可以定义bool和boolean类型,但最后都会被转换成tinyint(1)格式进行保存。因此,创建表的时候将一个字段定义为bool和boolean,数据库中真实定义的是tinyint(1)格式。
- 在
【问题 3】MariaDB 中如何存储 JPG 图片和 MP3 音乐?
- 一般情况下,数据库中不直接存储图片和音频文件,而是存储图片和音频文件的路径。如果有需要在
MariaDB中存储,就选择blob类型,因为blob类型可以用来存储二进制类型的文件。
- 一般情况下,数据库中不直接存储图片和音频文件,而是存储图片和音频文件的路径。如果有需要在
2. 操作数据库
数据库是指长期存储在计算机内、有组织的和可共享的数据集合。
- 数据库操作
- 创建:
create database 数据库名; - 查看:
show databases; - 删除:
drop database 数据库名;
- 创建:
- 数据库引擎
- 查看:
show engines;
- 查看:
光说不练假把式
- 【练习】登录数据库系统之后,创建 student 和 teacher 数据库,之后删除 teacher 数据库
-- 1.登录数据库
bash> mysql -u'mysql' -p'admin'
-- 2.查看数据库已存在的数据库
sql> show databases;
-- 3.查看数据库系统支持的存储引擎类型
-- Transactions:事务处理;XA分布式交易处理规范;Savepoints:保存点
sql> show engines;
sql> show variables like 'storage_engine';
-- 4.创建指定数据库
sql> create database student;
sql> create database teacher;
-- 5.删除指定数据库
sql> drop database teacher;
常见问题以及解答
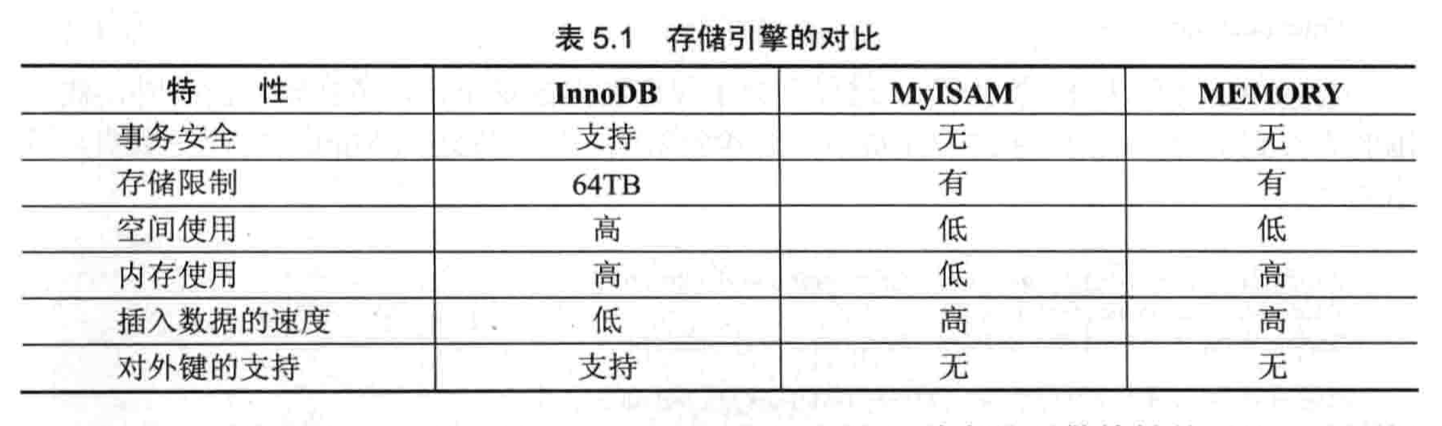
- 【问题 1】如何选择存储引擎?
- 同一个数据库中可以使用多种存储引擎的表。如果一个表要求较高的事务处理,可以选择 InnoDB 存储引擎。这个数据库中可以将查询要求比较高的表选择 MyISAM 存储引擎。如果该数据库中需要一个用于查询的临时表,可以选择 MEMORY 存储引擎。
- 【问题 2】如何修改默认存储引擎?
- 在 MariaDB 的安装目录下能够找到一个名为 my.ini 配置文件,通过修改 default-storage-engine 字段更改默认存储引擎。注意,该配置文件只有重启服务后才会生效。
1.3 增删改查表
表是数据库存储数据的基本单位,一个表包含若干个字段或记录。

- 约束规范
- 主键(primary key)
- 主键必须为唯一的
- 主键的值是非空的
- 主键可以是单一的字段,也可以使多个字段的组合
- 外键(foreign key)
- 外键用于建立表与表之间的关系,可以为空值
- 外键必须依赖于数据库中已经存在的父表的主键,且数据类型必须一致
- 非空约束(not null)
- 非空性是指字段的值不能为空值
- 唯一性约束(unique)
- 唯一性是指所有记录中该字段的值不能重复出现
- 自动增加(auto_increment)
- 用于为表中插入的新纪录自动生成唯一的 ID 值
- 约束的字段必须为主键的一部分,且该字段可以是任意整数类型
- 默认值(default)
- 不指定的值的时候自动添加默认值
- 主键(primary key)
- 创建数据库
create table 表名 (属性 类型);
- 查看数据库
desc 表名;show create table 表名;
- 修改数据库
- 修改表名:
alter table 旧表名 rename [to] 新表名; - 修改字段:
alter table 表名 modify 属性名 数据类型; - 修改位置:
alter table 表名 modify 属性名1 数据类型 first|after 属性名2; - 修改字段:
alter table 表名 change 旧属性名 新数据类型; - 增加字段:
alter table 表名 add 属性名1 数据类型 [完整性约束] [first|after 属性名2]; - 删除字段:
alter table 表名 drop 属性名; - 删除外键:
alter table 表名 drop foreign key 外键别名; - 存储引擎:
alter table 表名 engine='存储引擎名';
- 修改表名:
- 删除数据库
drop table 表名;
光说不练假把式
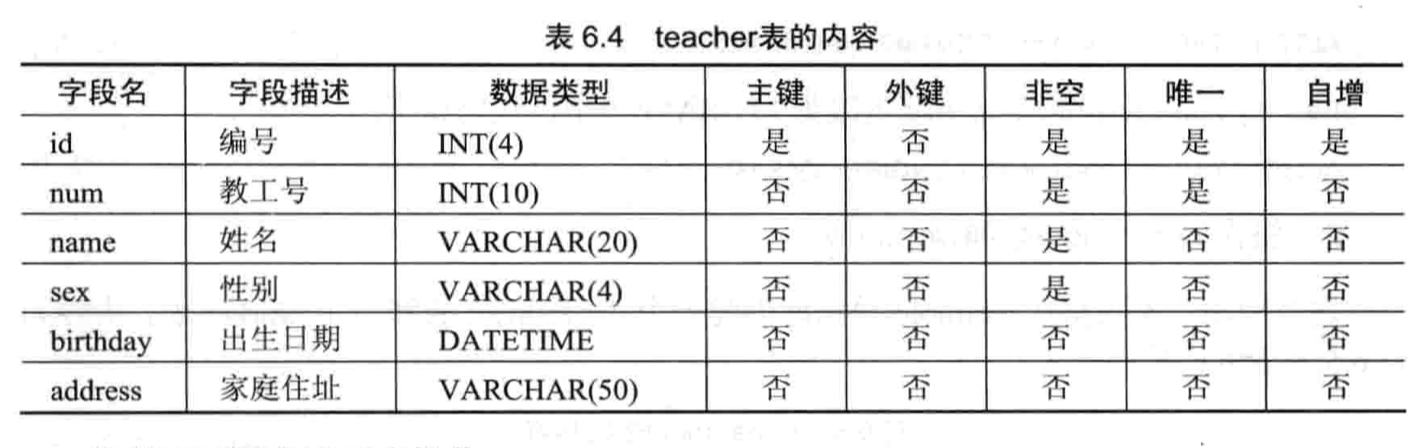
- 【练习 1】将在 school 数据库创建一个 teacher 表
- 创建 school 数据库
- 创建 teacher 表并查看表结构
- 将 teacher 表的 name 字段的数据类型改为 varchar(30)
- 将 birthday 字段的位置改到 sex 字段前面
- 将 num 字段改名为 t_id
- 将 teacher 表的 address 字段删除
- 在 teacher 表中增加名为 wages 的字段,数据类型为 float
- 将 teacher 表改名为 teacherInfo
- 将 teacher 表的存储引擎更改为 MyISAM 类型
-- 1.创建school数据库
sql> create database school;
-- 2.创建teacher表并查看表结构
sql> use school;
sql> create table teacher(
-> id int(4) not null unique primary key auto_increment,
-> num int(10) not null unqiue,
-> name varchar(20) not null,
-> sex boolean not null,
-> birthday datetime,
-> langages varchar(20) default 'English',
-> address varchar(50)
-> );
-- 简单和详细查看表结构
sql> desc school;
sql> show create table school;
-- 3.将teacher表的name字段的数据类型改为varchar(30)
sql> alter table teacher modify name varchar(30) not null;
-- 4.将birthday字段的位置改到sex字段前面
sql> alter table teacher modify birthday datetime after name;
-- 5.将num字段改名为t_id
sql> alter table teacher change num t_id int(10) not null;
-- 6.将teacher表的address字段删除
sql> alter table teacher drop address;
-- 7.在teacher表中增加名为wages的字段,数据类型为float
sql> alter table teacher add wages float first;
-- 8.将teacher表改名为teacherInfo
sql> alter table teacher rename teacherInfo;
-- 9.将teacher表的存储引擎更改为MyISAM类型
sql> alter table teacherInfo engine=MyISAM;
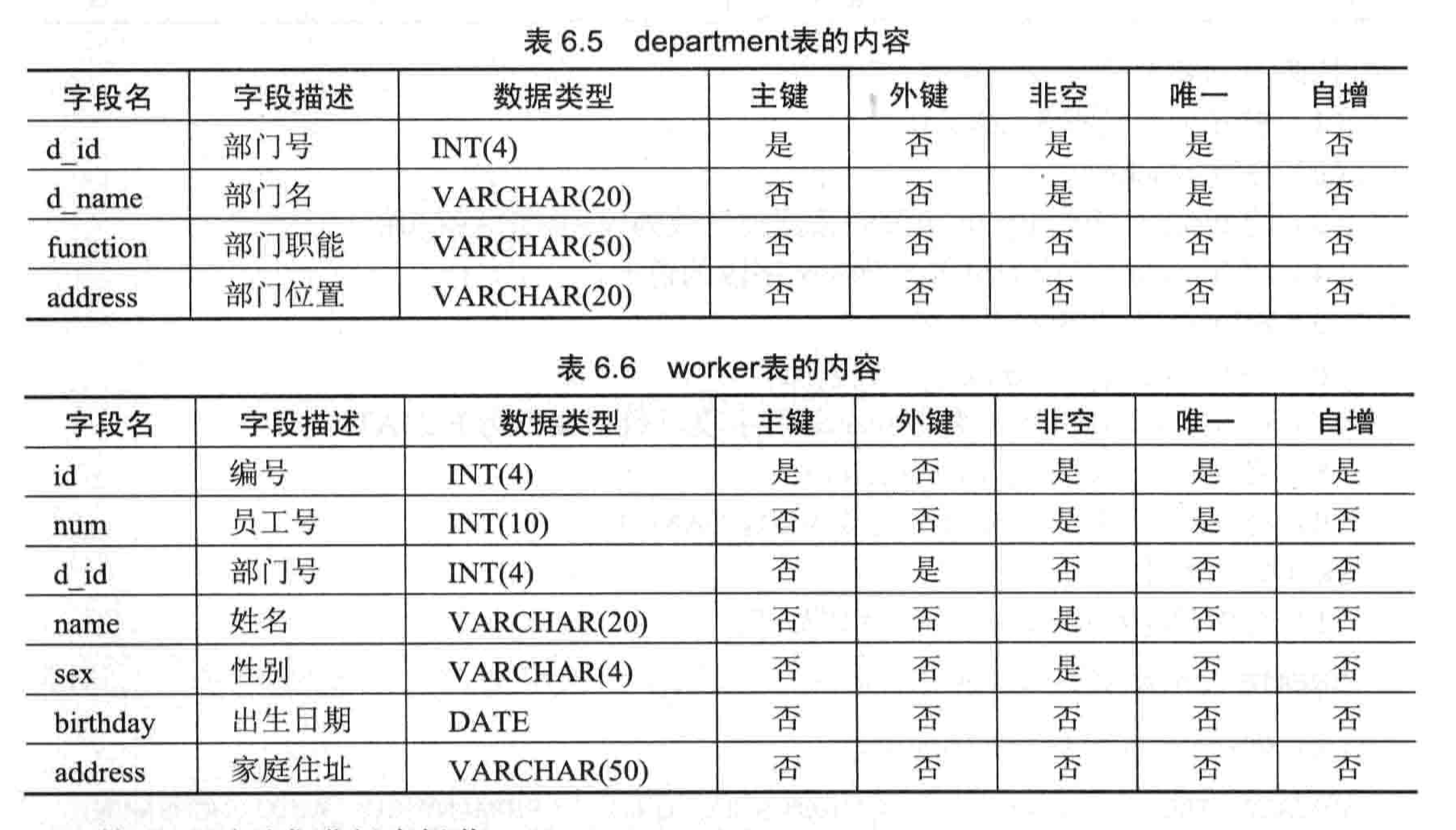
- 【练习 2】创建 department 和 worker 表
- 在 example 数据库下创建 deparment 和 worker 表
- 删除 deparment 表
-- 1.在example数据库下创建deparment表
sql> use example;
sql> create table department(
-> d_id int(4) not null unique,
-> d_name varchar(20) not null nuique,
-> function varchar(50),
-> address varchar(50),
-> primary key(d_id)
-> );
-- 2.在example数据库下创建worker表
sql> create table woker(
-> id int(4) not null unique primary key auto_increment,
-> num int(10) not null unique,
-> d_id int(4),
-> name varchar(20) not null,
-> sex varchar(4) not null,
-> birthday date,
-> address varchar(50),
-> constraint worker_fk foreign key(d_id) references department(d_id)
-> );
-- 3.删除deparment表,提示存在外间约束
sql> drop table department;
-- 4.删除worker表的外键约束
sql> alter table worker drop foreign key worker_fk;
-- 5.重新删除deparment表
sql> drop table department;
-- 补充: 多外键的设定
sql> create table example2(
-> id int primary key,
-> stu_id int,
-> course_id int,
-> constraint c_fk foreign key(stu_id, course_id) references example1(stu_id, course_id)
-> );
常见问题以及解答
【问题 1】如何设置外键?
- 子表的外键必须依赖父表的某个字段,因此父表必须优先于子表创建。而且,父表中的被依赖字段必须是主键或者组合主键的一个。如果不满足这样的条件,子表将不能创建成功。
【问题 2】为什么自增不能设置默认值?
- 自增字段必须是主键的一部分,而且一个表有且只能有一个自增字段,它可以为任意合法的整数类型。自增字段是没有默认值的,数值从 1 开始增加逐个增加。
【问题 3】如何删除父表?
- 因为子表的外键约束限制了父表的删除,而且删除过程比较麻烦。
- 第一种方法:先删除子表的外键约束,然后再删除父表,达到删除父表的目的。
- 第二种方法:先删除子表再删除父表,这样完全可以达到删除父表的目的,但是必须要牺牲子表。
4. 索引
索引是一种特殊的数据库结构,可以用来快速查询数据库表中的特定记录,提高数据库性能。
索引的含义
- 在 MariaDB 中,索引的数据类型都可以被索引。索引由数据库表中一列或多列组合而成,用于提高查询的速度。通过索引,查询数据时可以不必读完记录的所有信息,而只是查询索引列。否则,数据库系统将读取每条记录的所有信息进行匹配。
- 不同的存储引擎定义了每个表的最大索引数和最大索引长度。所有存储引擎对每个表至少支持 16 个索引,总索引长度至少 256 字节。索引有两种存储类型,包括 B 型树(
btree)和哈希(hash)索引。InnoDB 和 MyISAM 存储引擎支持 BTREE 索引,MEMORY 存储引擎支持 HASH 索引和 BTREE 索引,默认为前者。
索引的优缺点
- [优点] 创建索引的最主要原因是,其可以提高检索数据的速度
- [优点] 对于有依赖关系的子表和父表之前的联合查询时,可以提高查询速度
- [优点] 使用分组和排序子句进行数据查询时,显著节省查询中分组和排序的时间
- [缺点] 创建和维护索引需要消耗时间,消耗时间的数量随着数据量的增加而增加
- [缺点] 索引需要占用物理空间,每一个索引要占一定的物理空间
- [缺点] 增加、删除和修改数据时,要动态的维护索引,造成数据的维护速度降低了
索引的分类
- 普通索引:不需要附件任何限制条件;且可以创建在任何数据类型上
- 唯一性索引:使用 unique 参数设置唯一性索引;该索引的值必须是唯一的;主键是一种特殊的唯一索引
- 全文索引:使用 fulltext 参数设置全文索引;只能创建在 char/varchar/text 字段上;查询数据量较大时使用
- 单列索引:在表的单个字段上创建索引;单列索引可为普通索引/唯一性索引/全文索引,保证只有一个字段
- 多列索引:在表的多个字段上创建索引;只有查询条件中使用了第一个字段时,索引才会被使用
- 空间索引:使用 spatial 参数设置空间索引;只能建立在空间数据类型上;空间数据类型 geometry/point 等
索引的设计原则
- 选择唯一性索引
- 为经常需要排序、分组和联合操作的字段建立索引
- 为长作为查询条件的字段建立索引
- 限制索引的数目
- 尽量使用数据量少的索引
- 尽量使用前缀来索引
- 删除不再使用或者很少使用的索引
索引创建和删除方式
- [创建] 创建表的时候创建索引
create table 表名 ... [unique|fulltext|spatial] index [别名] (属性名[(长度)]) [asc|desc])
- [创建] 在已经存在的表上创建索引
create [unique|fulltext|spatial] index 索引名 on 表名(属性名 [(长度)] [asc|desc])
- [创建] 用 alter 语句来创建索引
alter table 表名 add [unique|fulltext|spatial] index 索引名(属性名 [(长度)] [asc|desc])
- [删除] 删除已有的索引
drop index 索引名 on 表名
- [创建] 创建表的时候创建索引
光说不练假把式
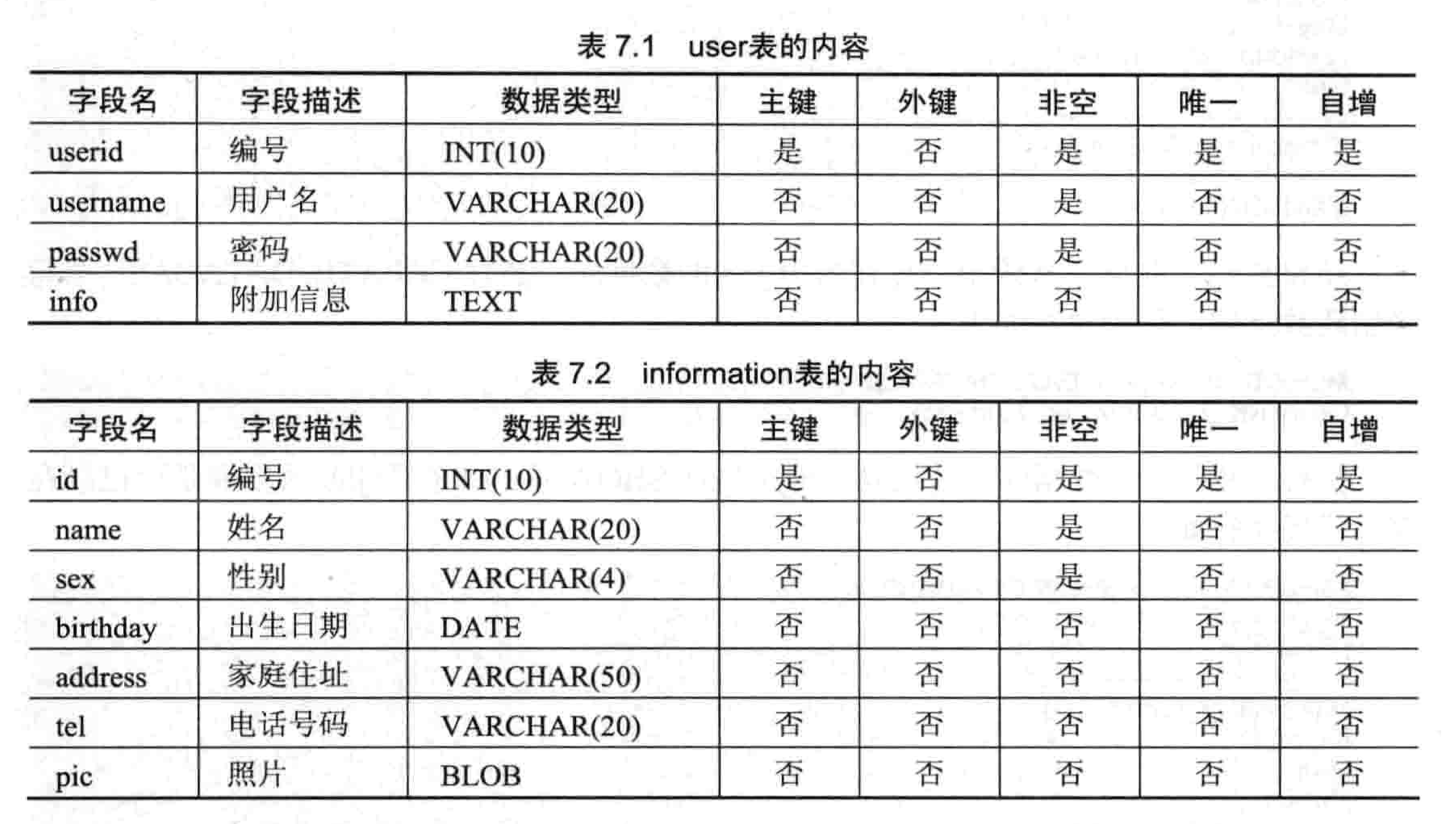
- 【练习 1】在 job 数据库中创建 user 和 information 表
- 创建 job 数据库
- 创建 user 表
- 在 user 表中,存储引擎为 MyISAM 类型
- 在 user 表中,userid 字段上创建名为 index_uid 的唯一性索引,降序排列
- 在 user 表中,username 和 passwd 字段创建名为 index_user 的多列索引
- 在 user 表中,info 字段上创建名为 index_info 的全文索引
- 创建 information 表
- 在 information 表中,name 字段创建名为 index_name 的单列索引,索引长度为 10
- 在 information 表中,birthday 和 address 字段上创建名为 index_bir 的多列索引,判断索引的使用情况
- 用 alter 语法在 id 字段上创建名为 index_id 的唯一性索引,升级排列
- 删除 user 表的 index_user 索引
- 删除 information 表上的 index_name 索引
-- 1.创建job数据库
sql> create database job;
-- 2.创建user表
sql> create table user(
-> userid int(10) not null unique primary key auto_increment,
-> username varchar(20) not null,
-> passwd varchar(20) not null,
-> info text,
-> unique index index_uid(userid desc),
-> index index_user(username, passwd),
-> fulltext index index_info(info)
-> )engine=MyISAM;
-- 3.创建information表
sql> create table information(
-> id int(10) not null unique primary key auto_increment,
-> name varchar(20) not null,
-> sex varchar(4) not null,
-> birthday date,
-> address varchar(50),
-> tel varchar(20),
-> pic blob
-> );
-- 4.name字段创建名为index_name的单列索引(create index)
sql> create index index_name on information(name(10));
-- 5.birthday和address字段上创建名为index_bir的多列索引(create index)
sql> create index index_dir on information(birthday, address);
-- 6.id字段上创建名为index_id的唯一性索引(alter table)
sql> alter table information add index index_id(id asc);
-- 7.删除user表的index_user索引
sql> drop index index_user on user;
-- 8.删除information表上的index_name索引
sql> drop index index_name on information;
-- 查询索引是否被使用了
sql> explain select * from index1 where id=1 \G;
常见问题以及解答
【问题 1】为什么创建索引导致插入速度变慢?
- 索引可以提高查询的速度,但是会影响到插入记录的速度。因为,向有索引的表中插入记录时,数据库系统会按照索引进行排序。当有大量数据插入时,尤为明显。这种情况下,最好的办法是先删除表中的索引,然后插入数据,插入完成之后在创建索引。
【问题 2】为什么创建的多列索引没有使用到?
- 使用多列索引时一定要注意,只有使用了索引中的第一个字段时才会触发索引。如果没有使用索引中的第一个字段,那么这个所列索引就不会起作用了。因此,在优化查询速度时,可以考虑多列索引。
5. 视图
视图是为了方便用户对数据的操作。
- 视图的含义
- 视图是从一个或多个表中导出来的表,是一种虚拟存在的表,还可以从已经存在视图的基础上定义。
- 数据库中只存放了视图的定义,并没有存放视图中的数据,数据还是存放在原来的表中。
- 因此,视图中的数据时依赖于原来的表中数据的。一旦表中数据发生了变更,显示的视图中的数据也会发生变化。
- 在 MariaDB 的视图不支持输入参数的功能,因此交互性上还有欠缺。但对于变化不是很大的操作,使用视图可以很大程度上简化用户的操作。
- 视图的作用
- 使操作简单化
- 增加数据的安全性
- 提高表的逻辑独立性
- 创建视图
- 语法格式
create [algorithm={undefined|merge|temptable}] view 视图名 [(属性清单)] as select 语句 [with [cascaded|local] check option]
- 视图算法
- undefined 表示将自动选择所要使用的算法;merge 表示将使用视图的语句和定义合并起来,使得视图定义的某一部分取代语句的对应部分
- temptable 表示将视图的结果存入临时表,然后使用临时表执行语句
- 可选参数
- with check option 表示更新视图时要保证在该视图的权限范围之内;cascaded 表示更新视图时要满足相关视图和表的条件
- 且为默认参数;local 表示更新视图时,要满足该视图本身的定义条件
- 语法格式
- 查看视图
- 查看视图基本机构
desc 视图名;
- 查看视图表的信息
show table status like '视图名';
- 查看视图创建信息
show create view 视图名;
- 在 views 表的视图信息
select * from information_schame.views;
- 查看视图基本机构
- 修改视图
- 通过 create 方式
create or replace [algorithm={undefined|merge|temptable}] view 视图名 [(属性清单)] as select 语句 [with [cascaded|local] check option]
- 通过 alter 方式
alter [algorithm={undefined|merge|temptable}] view 视图名 [(属性清单)] as select 语句 [with [cascaded|local] check option]
- 通过 create 方式
- 更新和删除视图
- 更新语法
update 视图名称 set [属性清单];
- 删除语法
drop view [if exists] 视图名列表 [restrict|cascade]
- 更新语法
光说不练假把式
- 【练习 1】基础知识点热热身
-- 1.确认当前用户是否有创建视图的权限
sql> select Select_priv,Create_view_priv from mysql.user where user='用户名';
-- 2.更新视图
sql> update department_view3 set name='科研部',function='Mweb',address='233号';
sql> update department set d_name='科研部',function='Mweb',address='233号' where d_id=1001;
-- 3.在单表上创建视图
sql> create view department_view1 as select * from department;
sql> create view
-> department_view2(name,function,location)
-> as select d_name,function,address from department;
-- 4.在多表上创建视图
sql> create algorithm=merge view
-> worker_view1(name,department,sex,age,address)
-> as select name,department.d_name,sex,2013-birthday,address
-> from department,worker where department.d_id=worker.d_id
-> with local check option;
-- 5.更新视图
sql> create or replace algorithm=temptable
-> view department_view1(department,function,location)
-> as select d_name,function,address from deparment;
sql> alter view department_view2(department,name,sex,location)
-> as select d_name,worker.name,worker.sex,address
-> from deartment,worker where department.d_id=worker.d_id
-> with check option;
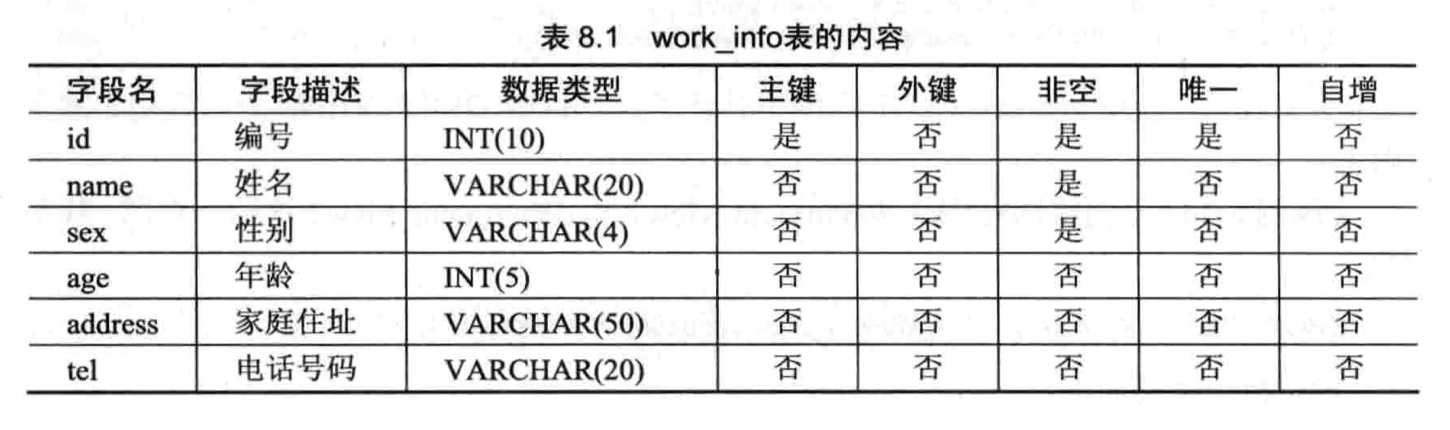
- 【练习 2】将在 test 数据库中 work_info 表上进行视图操作
- 创建 work_info 表
- 向表中插入几条记录
- 创建 info_view 视图;选出 age>20 的记录创建视图并加上限制条件
- 查看视图 info_view 的基本结构和详细结构
- 查看视图 info_view 的所有记录
- 修改视图 info_view,使其显示 age<20 的信息,其它条件不变
- 更新视图 info_view,将 id 为 3 的记录设置 sex 为 M
- 删除视图 info_view
-- 1.创建work_info表
sql> create table work_info(
-> id int(10) not null unique primary key,
-> name varchar(20) not null,
-> sex varchar(4) not null,
-> age int(5),
-> address varchar(50),
-> tel varchar(20)
-> );
-- 2.插入记录
sql> insert into work_info values(1, '张三', 'M', 18, '北京市', '1234567');
sql> insert into work_info values(2, '李四', 'M', 22, '北京市', '2345678');
sql> insert into work_info values(3, '王五', 'F', 17, '永州市', '3456789');
sql> insert into work_info values(4, '赵六', 'F', 25, '阜新市', '4567890');
-- 3.创建info_view视图
sql> create algorithm=merge view
-> info_view(id,name,sex,address)
-> as select id,name,sex,address from work_info where age>20
-> with local check option;
-- 4.查看视图
sql> desc info_view;
sql> show create view info_view \G;
sql> select * from info_view;
-- 5.更新视图
sql> update info_view set sex='M' where id=3;
-- 6.删除视图
sql> drop view info_view;
常见问题以及解答
【问题 1】MariaDB 中表和视图的关系?
- [区别] 视图是按照 SQL 语句生成的一个虚拟的表
- [区别] 试图不占用实际物理空间,而表会占用物理空间
- [区别] 建立和删除视图只影响视图本身,不会影响实际的记录
- [联系] 视图是建立在表基础上的,依赖于表而存在
- [联系] 一个试图可以对应一个基本表,也可以对于多个基本表
- [联系] 视图是基本表的抽象,在逻辑意义上建立的新关系
【问题 2】为什么不能更新视图了?
- 视图中包含 sum()、count()、max()和 min()等函数
- 视图中包含 union、union all、distinct、group by 和 having 等关键字
- 常规视图(字符串常数)
- 视图中的 select 中包含子查询
- 由不可更新的视图导出的视图
- 创建视图时,algorithm 为 temptable 类型
- 视图对于表上存在没有默认值的列且该列没有包含在视图内
- 参数 cascaded 和 local 也对更新有影响
6. 触发器
触发器是由事件来触发某个操作的,事件可以为 insert 语句、update 语句和 delete 语句。
- 创建触发器
- 创建只有一个执行语句的触发器
create tigger 触发器名 before|after 触发事件 on 表名 for each row 执行语句;
- 创建只有多个执行语句的触发器
create trigger 触发器名 before|after 触发事件 on 表名 for each row begin 执行语句列表 end
- 创建只有一个执行语句的触发器
- 查看触发器
- 查看触发器的基本信息
show triggers;
- 查看触发器的详细信息
select * from information_schame.triggers trigger_name='触发器名';
- 查看触发器的基本信息
- 删除触发器
drop trigger 触发器名;
光说不练假把式
- 【练习 1】基础知识点热热身
-- 1.创建只有一个执行语句的触发器
-- create tigger 触发器名 before|after 触发事件 on 表名 for each row 执行语句;
sql> create trigger dept_trig1 defore insert on department for each row insert into trigger_time values(now());
-- 2.创建只有多个执行语句的触发器
-- create trigger 触发器名 before|after 触发事件 on 表名 for each row
-- begin
-- 执行语句列表
-- end
sql> delimiter &&
sql> create trigger dept_trig2 after delete
-> on department for each row
-> begin
-> insert into trigger_time values('first'),
-> insert into trigger_time values('second'),
-> end
-> &&
sql> delimiter ;
-- 3.查看触发器的基本信息
sql> show triggers \G;
-- 4.查看触发器的详细信息
sql> select * from information_schame.triggers trigger_name='触发器名';
-- 5.删除触发器
-- drop trigger 触发器名;
sql> drop trigger worker_trig;
sql> drop trigger job.worker_trig;
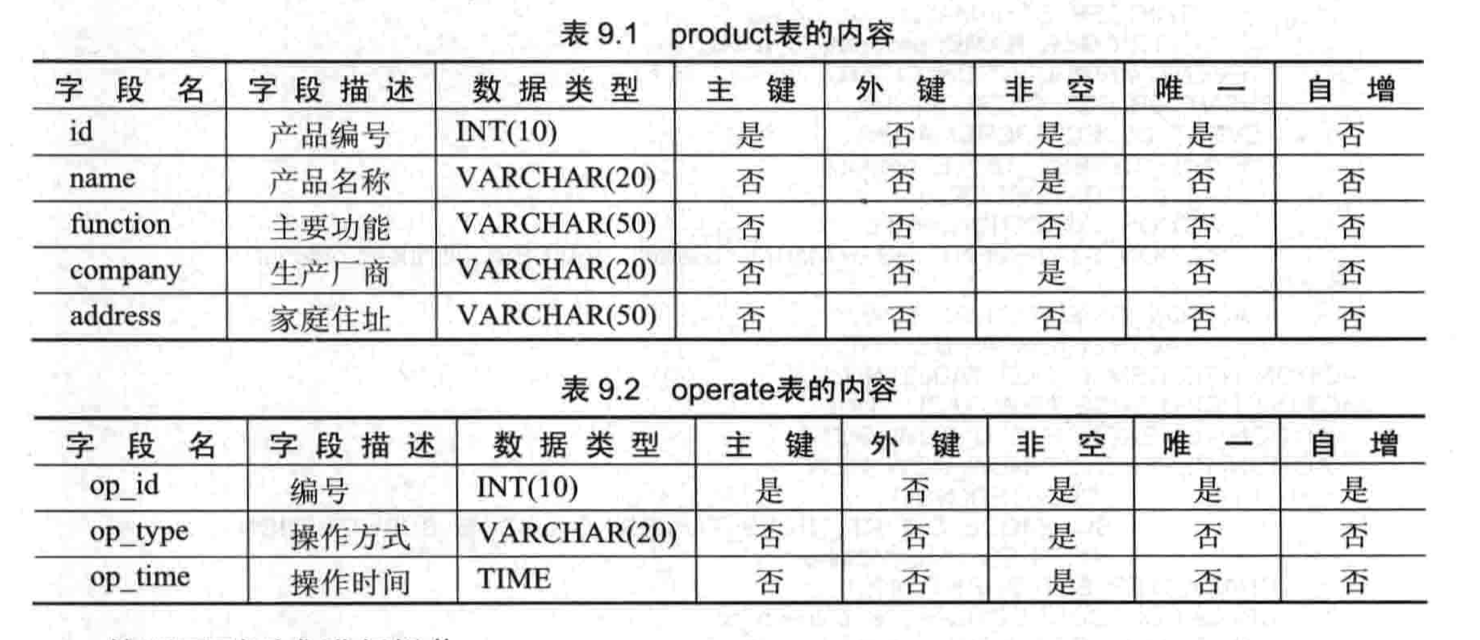
- 【练习 2】将在 product 表上创建 3 个触发器
- 创建 befor insert 触发器
- 创建 after update 触发器
- 创建 after delete 触发器
- 分别执行 insert、update 和 delete 操作,查看效果
- 删除其中两个触发器
-- 1.创建product表
sql> create table product(
-> id int(10) not null unique primary key,
-> name varchar(20) not null,
-> function varcahr(50),
-> company varchar(20) not null,
-> address varchar(50)
-> );
-- 2.创建operate表
sql> create table operate(
-> op_id int(10) not null unique primary key auto_increment,
-> op_name varchar(20) not null,
-> op_time time not null
-> );
-- 3.创建product_bf_insert触发器
sql> create trigger product_bf_insert before insert
-> on porduct for each row
-> insert into operate values(null, 'insert product', now()
-> );
-- 4.创建product_af_update触发器
sql> create trigger product_af_update after update
-> on product for each row
-> insert into operate values(null, 'update product', now()
-> );
-- 5.创建product_af_del触发器
sql> create trigger product_af_del after delete
-> on product for each row
-> insert into operate values(null, 'delete product', now()
-> );
-- 6.执行验证操作
sql> insert into product values(1, 'abc', '感冒药', 'def制药厂');
sql> update product set address='wyz制药厂' where id=1;
sql> delete from product where id=1;
-- 7.删除触发器
sql> drop trigger product_af_update;
sql> drop trigger product_af_del;
常见问题以及解答
【问题 1】 触发器的使用方式?
- 在 MariaDB 中,触发器执行的顺序是 before 触发器、表操作(insert/update/delete)、after 触发器。
【问题 2】无法创建多条语句的触发器?
- 在 MariaDB 中,系统默认的 SQL 程序的结束标志时分号,所有遇到分号的时候就会结束了。要解决这个问题,可以使用 delimiter 语句改编程序的结束标记,一般会设置为 delimiter &&格式。



